Reinforcement Learning in Computer Vision ¶
Contents¶
We will look at three Computer Vision tasks, namely-
- Object Detection
- Action Detection
- Visual Tracking
- For each task we will try answering these questions -
- What is the task?
- Can we identify the RL components -
- The MDP formulation
- State Space
- Action Space
- Reward System
- Network Architecture
- The MDP formulation
- Why use RL for this task?
Task 1: Object Detection ¶

What is the task?¶
Some Important KeyPoints -
- This is one of the fundamental Computer Vision Tasks
- This has been viewed as a Supervised Learning so far
- Some of the popular Approaches -
- Selective Search
- CPMC
- Edge Boxes (based on sliding windows)
- R-CNN
- Fast R-CNN
- Faster R-CNN
- YoLo
- ...
What's the idea here?¶
- A class-specific active detection model that learns to localize target objects known by the system.
- Model follows a top-down search strategy, which starts by analyzing the whole scene and then proceeds to narrow down the correct location of objects.
- Achieved by applying a sequence of transformations to a box that initially covers a large region of the image and is finally reduced to a tight bounding box.
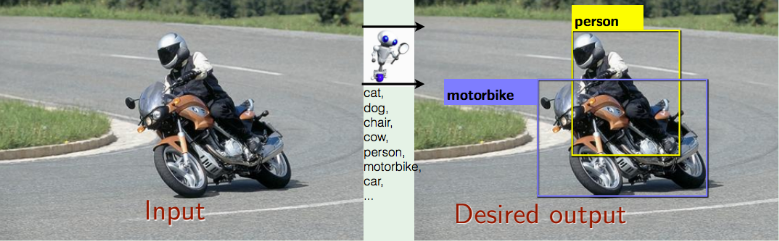
Example Output¶

How to look it as a RL problem?¶
Question 1: How to think of this as a Sequential Decision Making Problem?
Answer 1: At each time step, the agent should decide in which region of the image to focus its attention so that it can find objects in a few steps.
Question 2: How to cast this as a Markov Decision Process?
Answer 2: We cast the problem of object localization as a Markov decision process (MDP) since this setting provides a formal framework to model an agent that makes a sequence of decisions. We will try to identify the components of MDP, the set of actions A, a set of states S, and a reward function R.
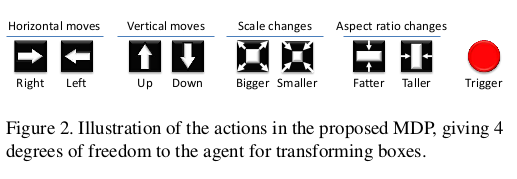
The set of actions A is composed of eight transformations that can be applied to the box and one action to terminate the search process.
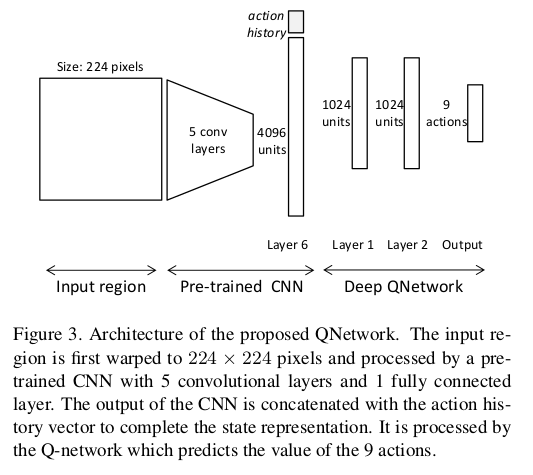
State Space?¶
- State Representation = tuple(o,h)
- o = feature vector of the observed region
- ((fc6) output => 4,096 dimensional feature vector to represent its content)
- h = vector with the history of taken actions
- The history vector encodes 10 past actions
- Actions encoded as a 9-dimensional binary vector
Motivation behind the history vector: Useful to stabilize search trajectories that might get stuck in repetitive cycles, improving average precision by approximately 3 percent points.
Rewards?¶
Motivation:
- Reward function R is proportional to the improvement that the agent makes to localize an object after selecting a particular action
- Measured using the Intersection-over-Union (IoU) between the target object and the predicted box at any given time
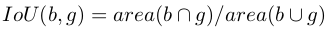
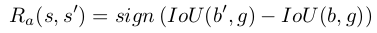
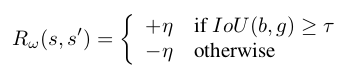
where, b = be the box of an observable region, and
g = the ground truth box for a target object
Explanation:
- Given a state s, those actions will be rewarded that result in a higher IOU with the groudtruth, otherwise the actions are penalised.
- For trigger action, reward is positive if final IOU with groundtruth is greater than a certin threshold, and negative otherwise.
- This reward scheme is binary r ∈ {−1, +1}, and applies to any action that transforms the box.
Network Architecture¶
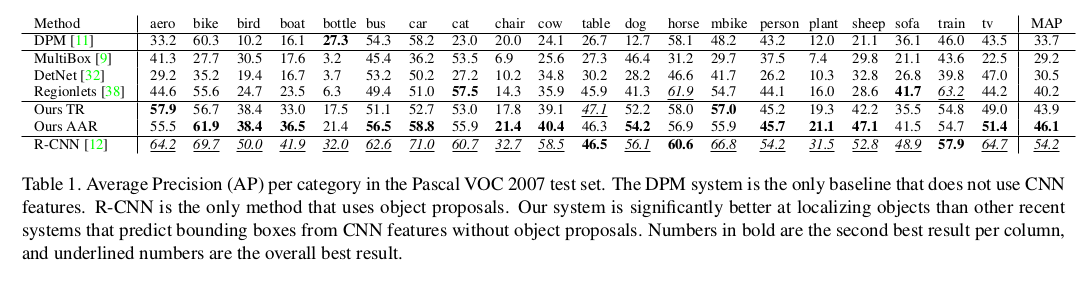
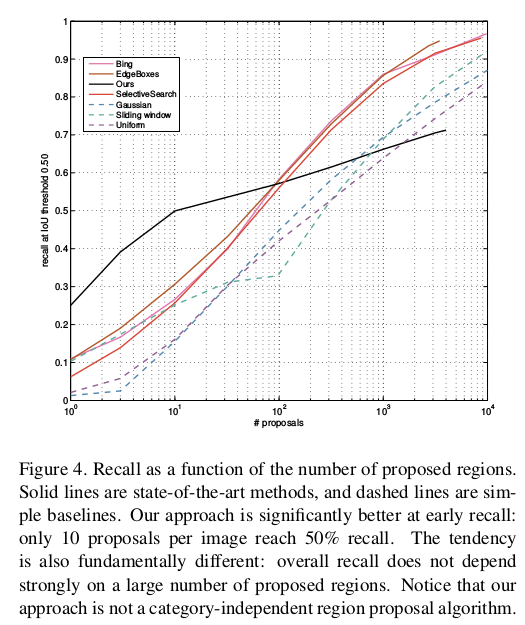
Some Quantitative Results¶
Some Qualitative Results¶


Why to use RL here?¶
Task 2: Action Detection ¶

What is the task?¶

- Does an action occur?
- When does the action occur?
Whats the idea here?¶
- A class-specific action-detection model.
- It learns to continually adjust the current region to cover th groundtruth more precisely in a self-adapted way
- This is achieved by applying a sequence of transformations to a temporal window that is initially placed in the video at random and finally finds and covers action region as large as possible.
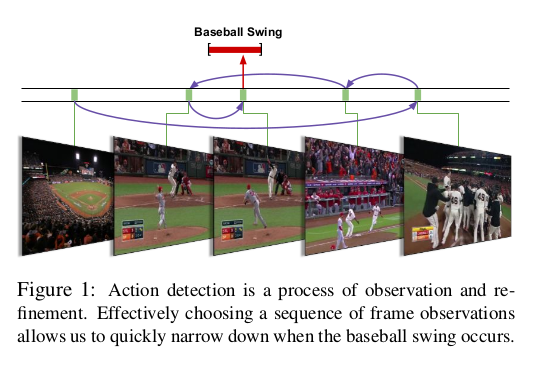
Example Output¶
How to look at it as a RL problem?¶
Question 1: How to cast this as a Markov Decision Process?
Answer 1: The problem is cast as a MDP, in which the agent interacts with the environment and makes a sequence of decisions to achieve the settled goal.
- In our formulation, the environment is the input video clip,
- in which the agent has an observation of the current video segment, called temporal window,
- and through the actions he restructures the position or span of the window, to achieve the goal of locating the actions precisely.
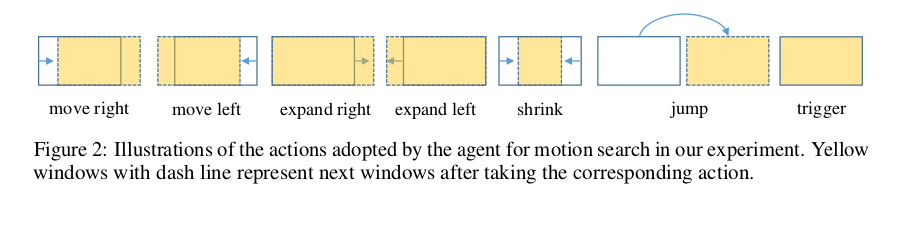
The idea behind this irregular action, is to translate the temporal window to a new position away from the current site to avoid that the agent traps itself round the present location when there is no motion occurin nearby.
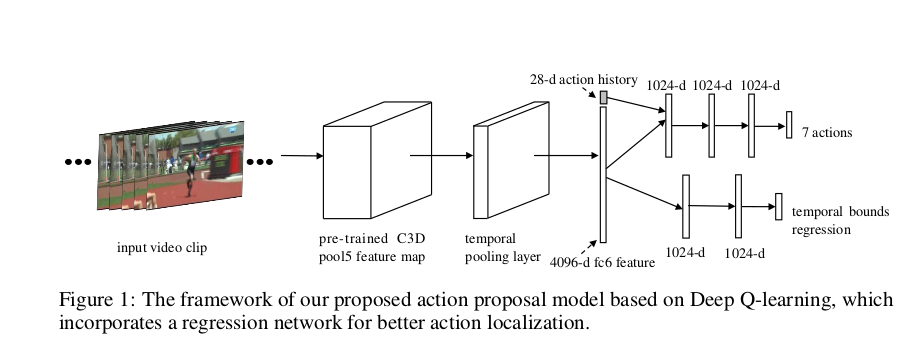
State Space?¶
- State Repreentation = composed of two components (current temporal window, history of actions taken)
- current temporal window => to describe the motion within the current window
- features extracted from C3D CNN model (pre-trained on Sports-1M)
- ((fc6) output => 4,096 dimensional feature vector to represent its content)
- history of actions taken = vector with the history of taken actions
- The history vector encodes 10 past actions
- Actions encoded as a 7-dimensional binary vector
Motivation behind the history vector: Useful to stabilize search trajectories that might get stuck in repetitive cycles, improving average precision by approximately 3 percent points.
Rewards?¶
Motivation:
- Reward function R awards the agent for actions that will bring about the improvement of motion localisation accuracy
- And, the agent is penalized for actions that leads to the decline of the accuracy
- Measured using the Intersection-over-Union (IoU) between the current attended temporal window and the groundtruth region of motion
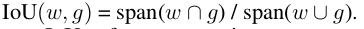
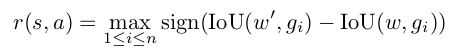
where, w and w' are attended windows corresponding to state s and s' respectively.
n = number of groundtruths within the video
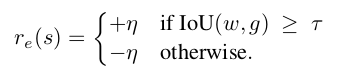
Network Architecture¶
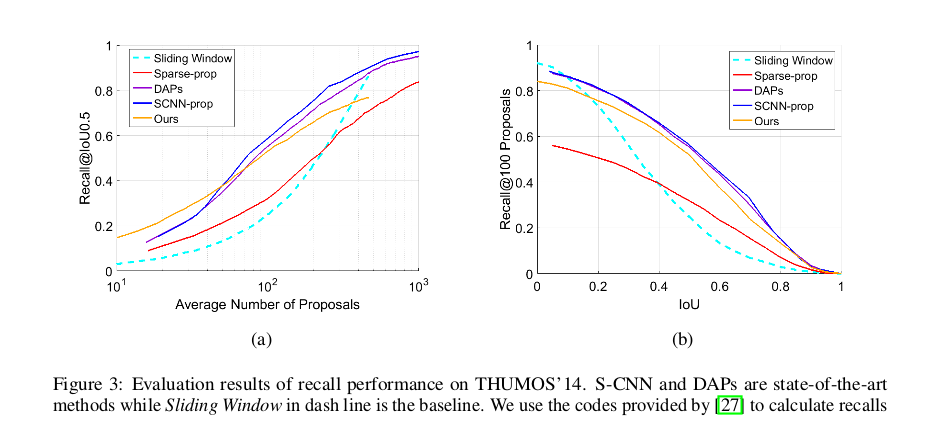
Some Quantitative Results¶
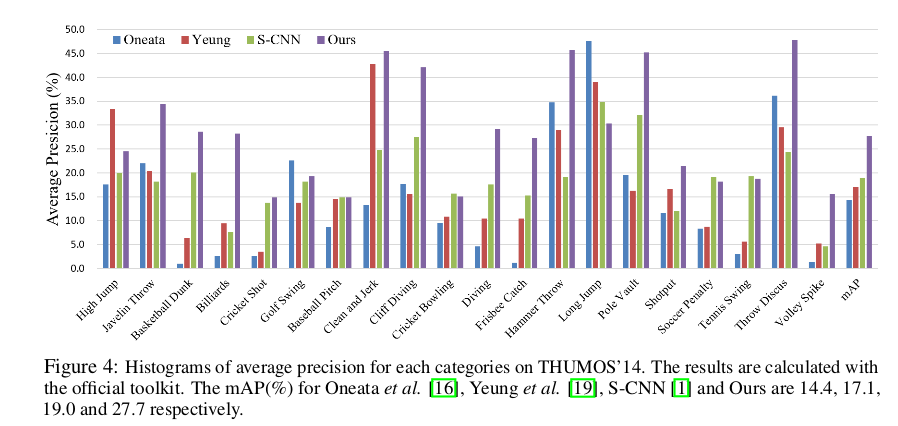
Some Qualitative Results¶
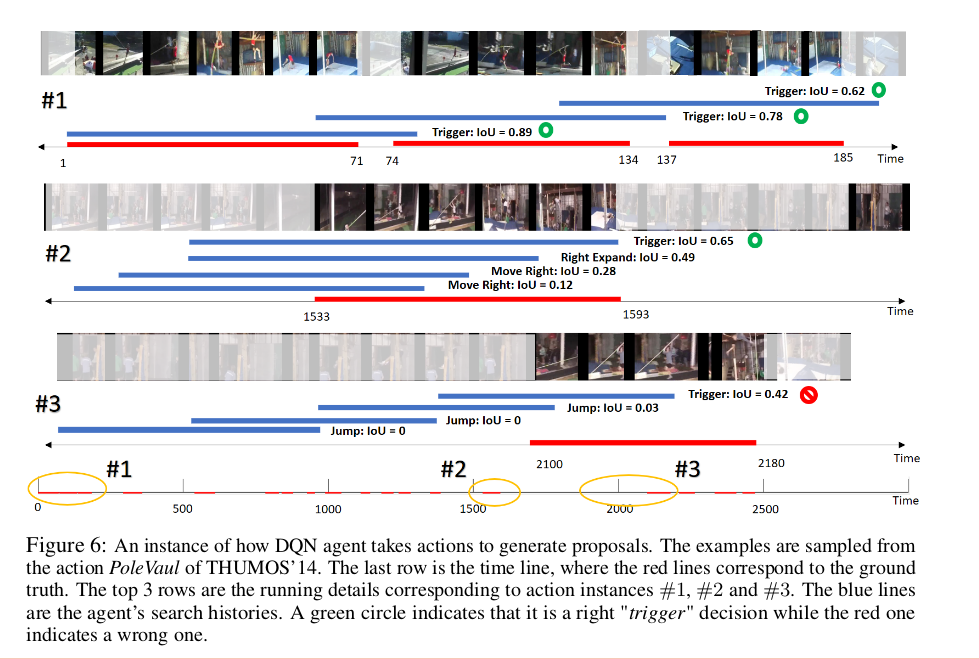
Why use RL here?¶
Task 3: Visual Tracking ¶

The Task at hand:¶
Single Line:¶
- Visual tracking solves the problem of finding the position of the target in a new frame from the current position.
Definition:¶
- Visual Tracking is the process of locating, identifying, and determining the dynamic configuration of one or many moving (possibly deformable) objects (or parts of objects) in each frame of one or several cameras
Tracking Challenges¶
- Object Modeling: how to define what an object is in terms that can be interpreted by a computer ?
- Appearance Change: The observation of an object changes according to many parameters (illumination conditions, occlusions, shape variation...)
- Kinematic Modelling: How to inject priors on object kinematic and interactions between objects.
Common hurdles¶
- Track initaition and termination
- Occlusion handling
- Merging/switching
- Drifting due to wrong update of the target model
Existing Methods¶
- Various Classical tracking methods, KLT Tracker etc.
- Recent CNN-Based:
- Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR'16
- Siamese Instance Search for Tracking, CVPR'16
- They still require computationally inefficient search algorithms, such as sliding window or candidate sampling.
Why RL:¶
- No post-processing: bounding box regression
- Fewer searching steps than sliding window or candidate sampling approaches
Focus of this paper:¶
Solution to existing works for:¶
1) Present better algorithm than the existing inefficient search algorithms that explore the region of interest and select the best candidate by matching with the tracking model, and
2) Presenting a method to train using unlabeled frames in a semi-supervised case.
MDP Formulation:¶
Visual tracking solves the problem of finding the position of the target in a new frame from the current position.
The proposed tracker dynamically pursues the target by sequential actions
The tracker is defined as an agent of whose goal is to capture the target with a bounding box shape.
The MDP Parameters: ¶
State Space:¶
- Goal : Capture Required Information.
- What useful Information must the state capture?
- State is defined by tuple ($p_t,d_t$)
- $p_t \in R^{112 \times 112 \times 3}$: denotes the image patch within the bounding box
- $d_t \in R^{110}$: represents the dynamics of actions denoted by a vector containing the previous $k$ actions at $t$-th iteration
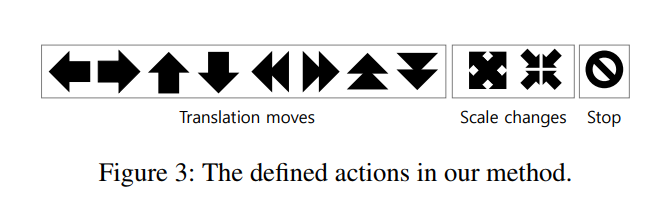
Action Space¶
- In this paper: Discrete Actions
- What can be the actions?
Transition Probabilities:¶
- After decision of action at in state $s_t$, the next state $s_{t+1}$ is obtained by the state transition functions.
- Will it be a stochastic output?
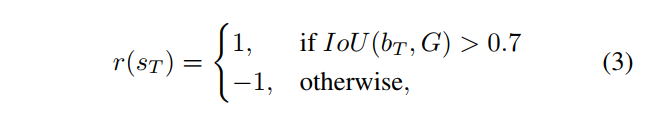
Network Architecture¶
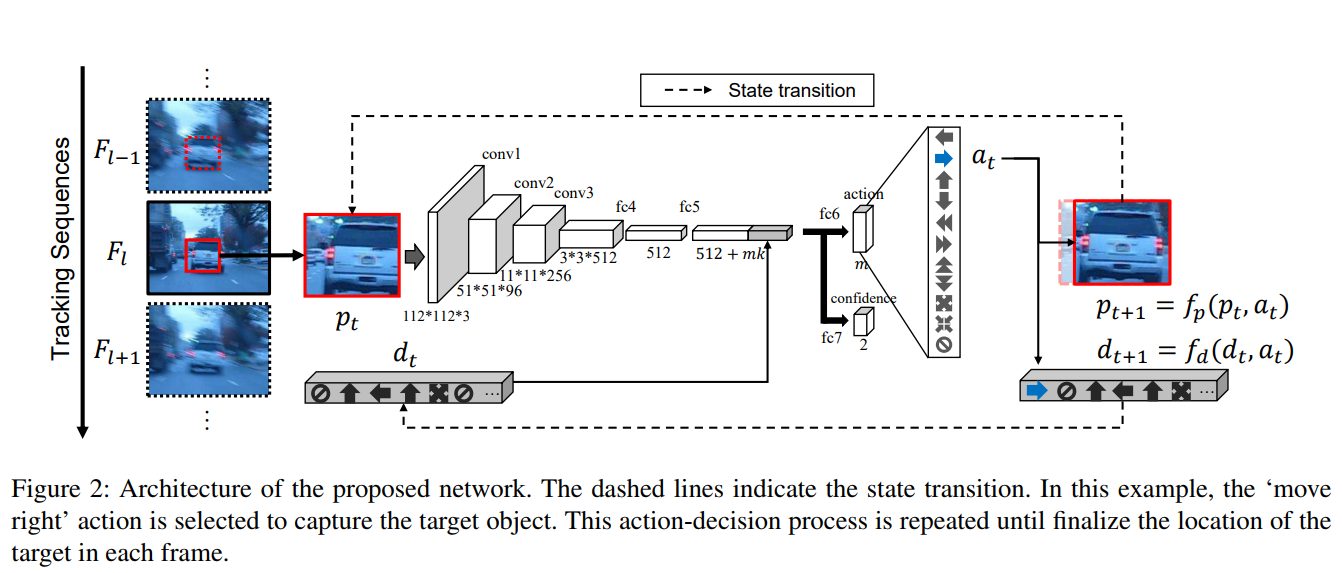
Action Selection:¶

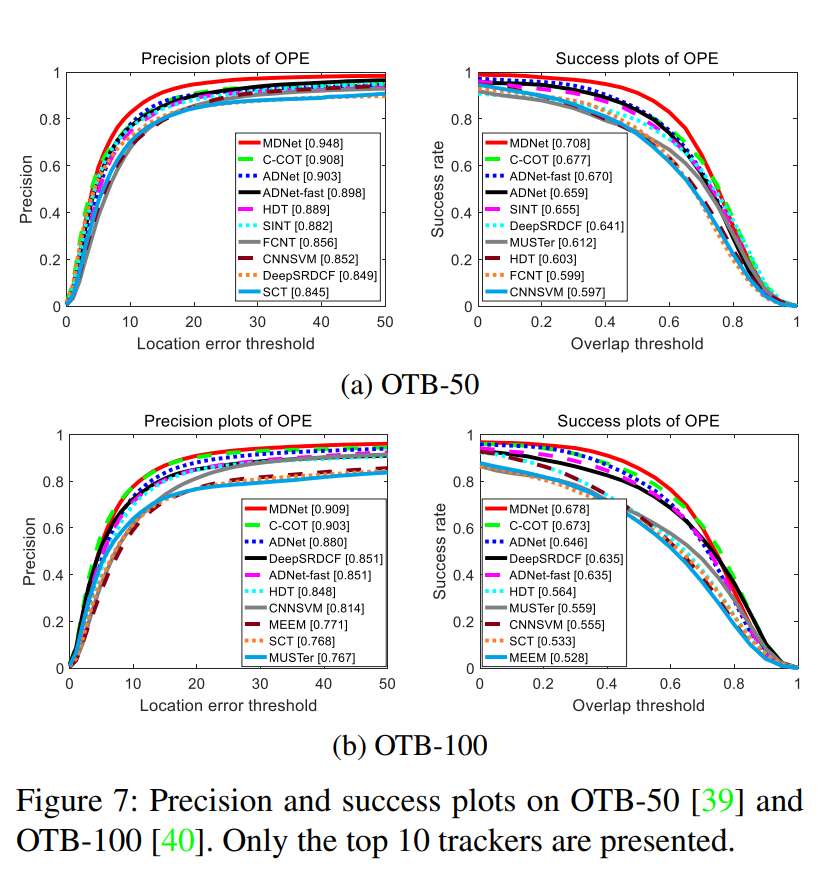
Results¶
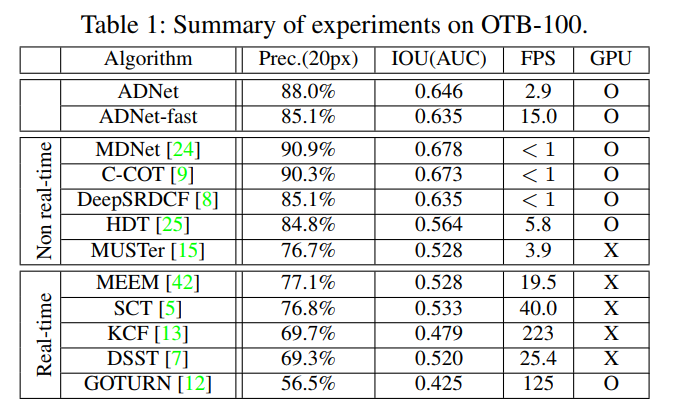
Results¶
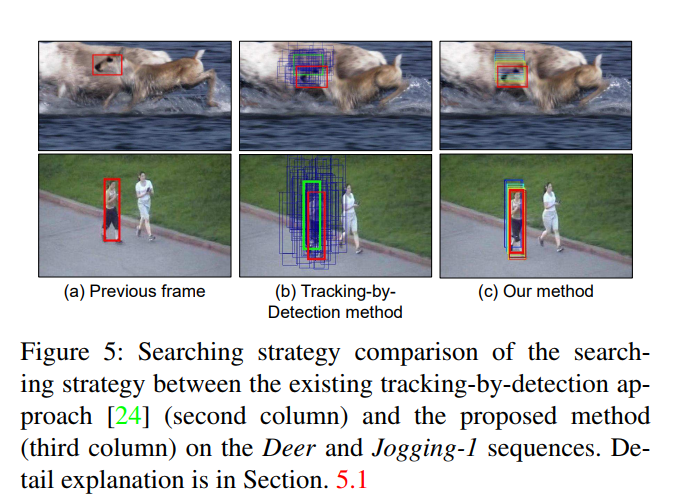
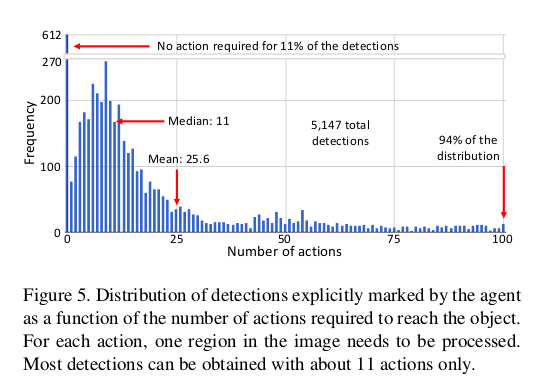
Analysis on the actions.¶
- most of the frames require fewer than five actions to pursue the target in each frame!