Batch Reinforcement Methods ¶
Batch Reinforcement Methods ¶
- Gradient descent is simple and appealing
- But it is not sample efficient
- Batch methods seek to find the best fitting value function
- Given the agent’s experience (“training data”)
Least Squares Prediction ¶

Stochastic Gradient Descent with Experience Replay ¶

Experience Replay in Deep Q-Networks (DQN) ¶

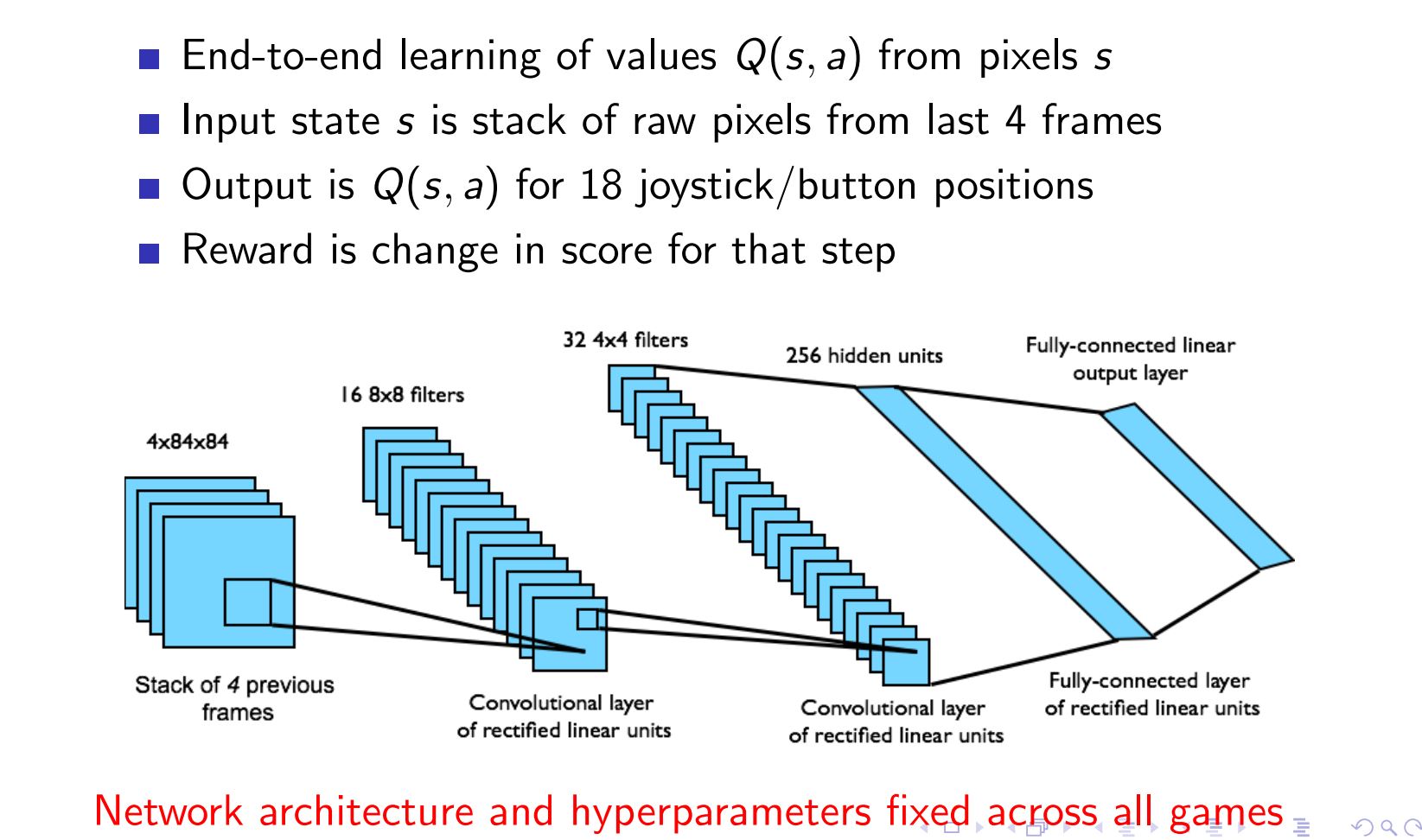
DQN in ATARI ¶
The model¶
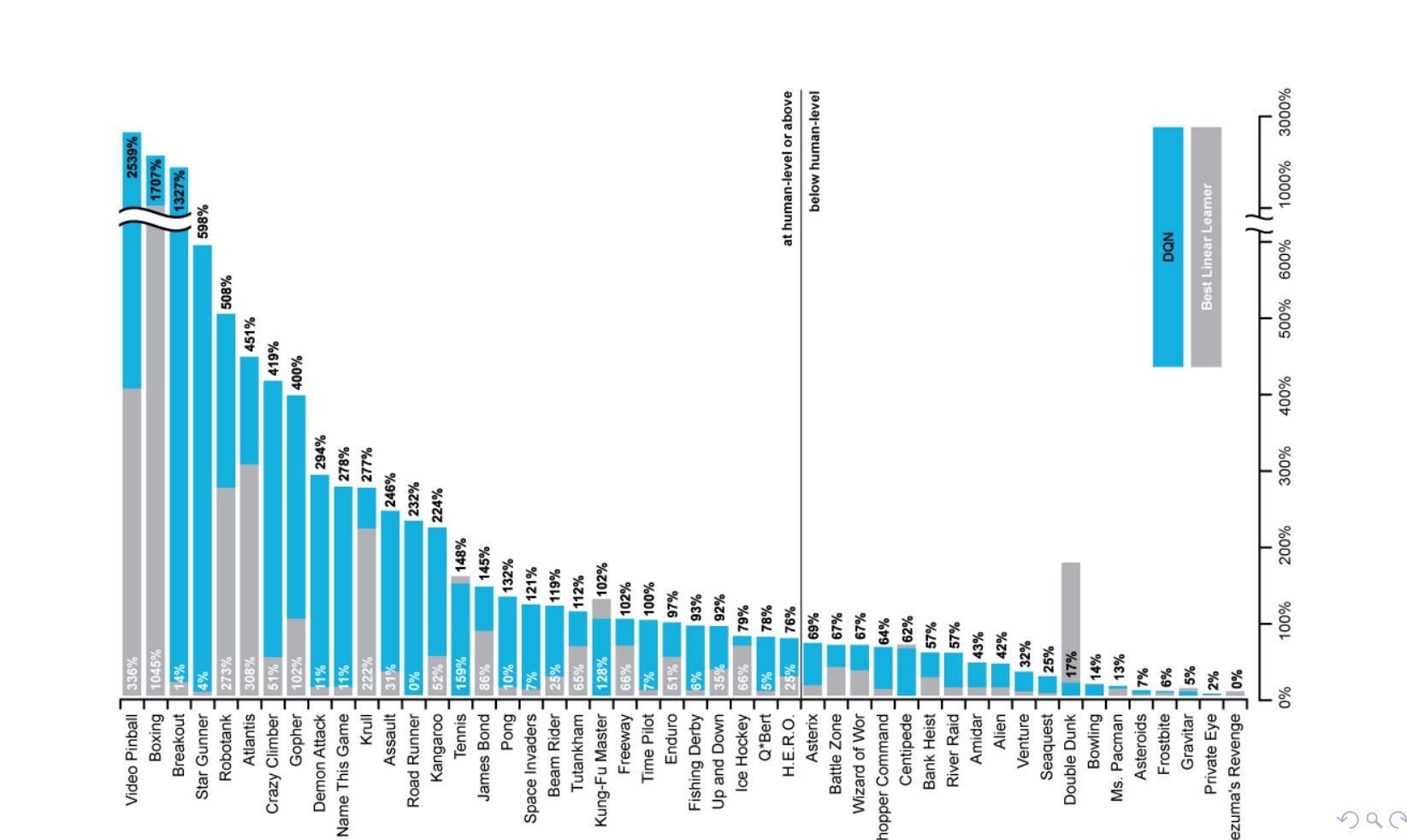
Performance¶
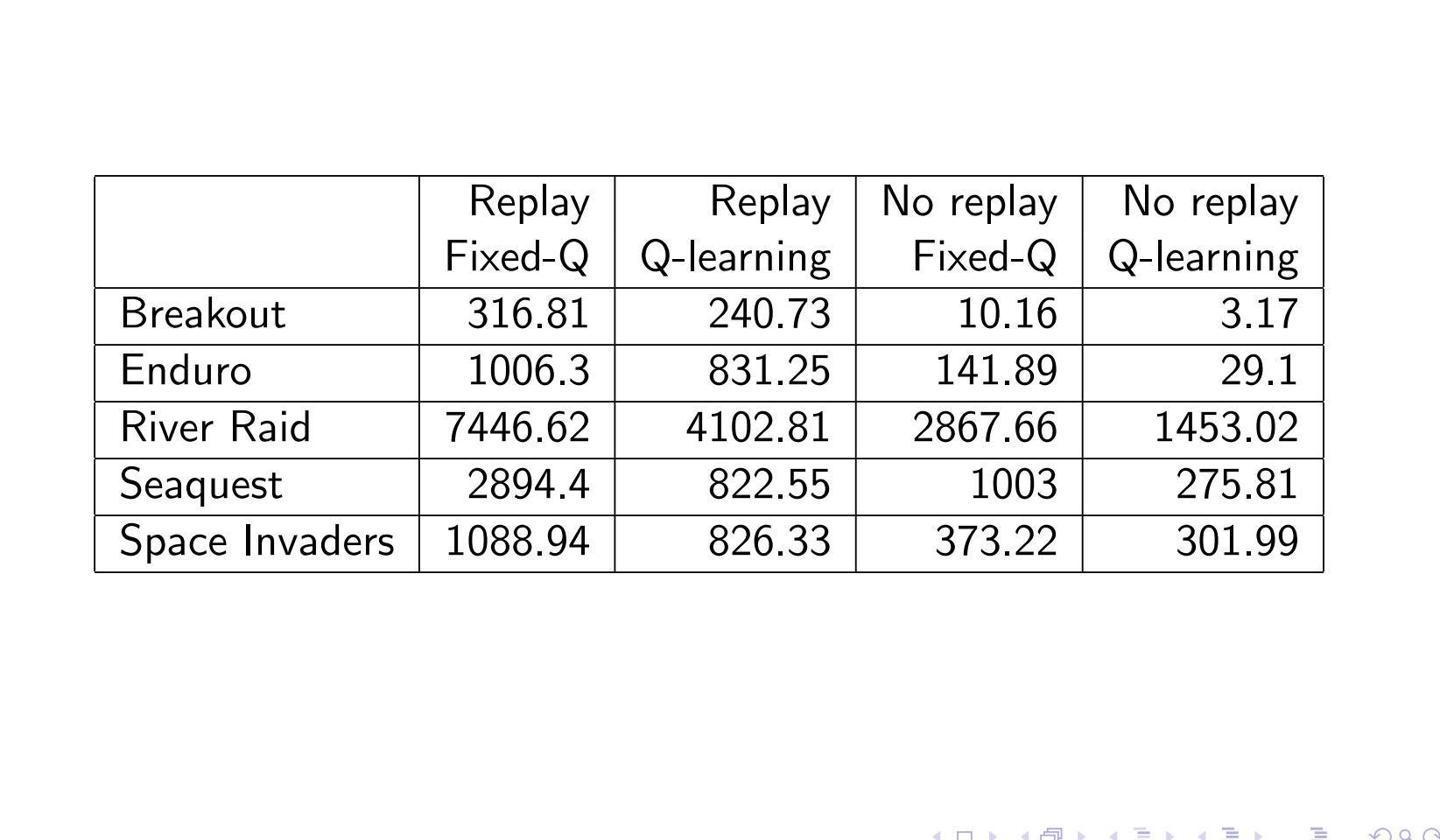
Benefits of Experience Replay and Double DQN¶
DQN Example and Code¶
CartPole Example¶
The agent has to decide between two actions - moving the cart left or right - so that the pole attached to it stays upright.
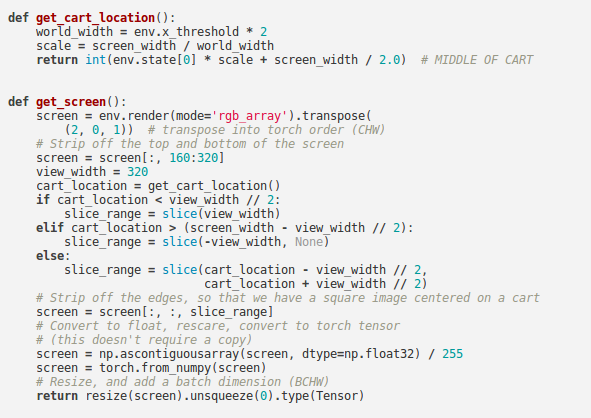
State Space¶
State is the difference between the current screen patch and the previous one. This will allow the agent to take the velocity of the pole into account from one image.
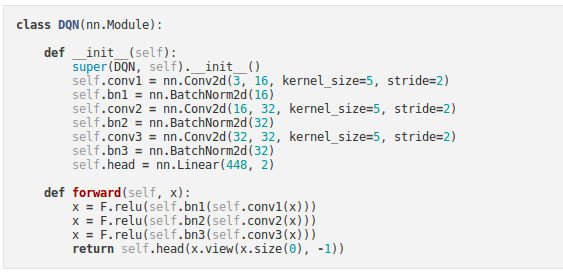
Q-network¶
- Our model will be a convolutional neural network that takes in the difference between the current and previous screen patches.
- It has two outputs, representing Q(s,left) and Q(s,right) (where s is the input to the network).
- In effect, the network is trying to predict the quality of taking each action given the current input.
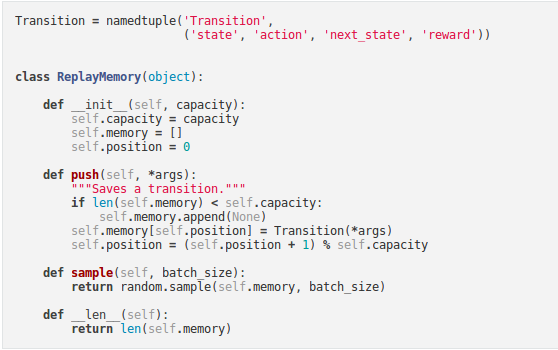
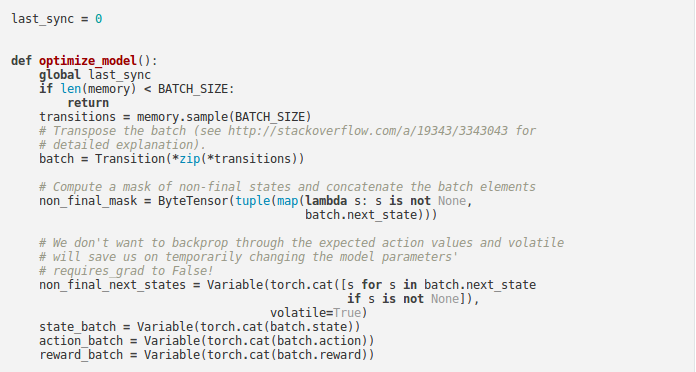
Replay Memory¶
- Experience replay memory is used for training the DQN.
- It stores the transitions that the agent observes, allowing us to reuse this data later.
- By sampling from it randomly, the transitions that build up a batch are decorrelated.
- It has been shown that this greatly stabilizes and improves the DQN training procedure.


Linear Least Squares Prediction ¶
Linear Least Squares Prediction ¶
- Experience replay finds least squares solution
- But it may take many iterations
- Using linear value function approximation $\hat{v}(s, w) = x(s)^Tw$
- We can solve the least squares solution directly
Linear Least Squares Prediction ¶

Linear Least Squares Prediction Algorithms ¶

In [ ]:
Linear Least Squares Prediction Algorithms ¶
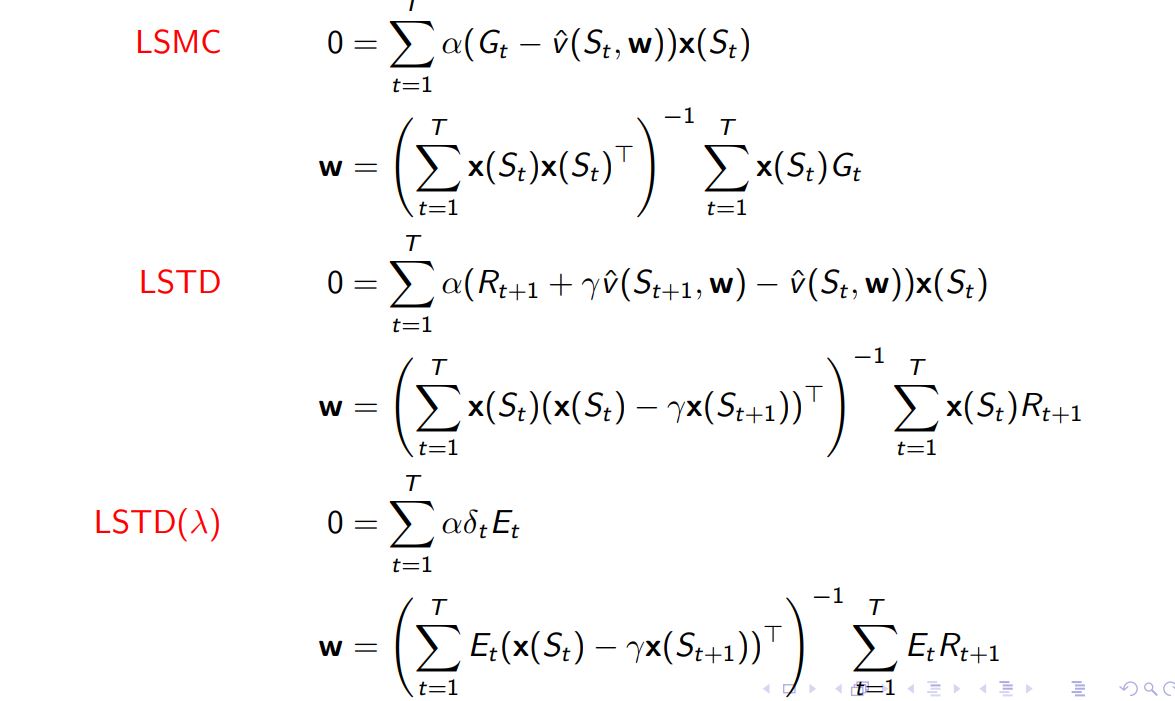
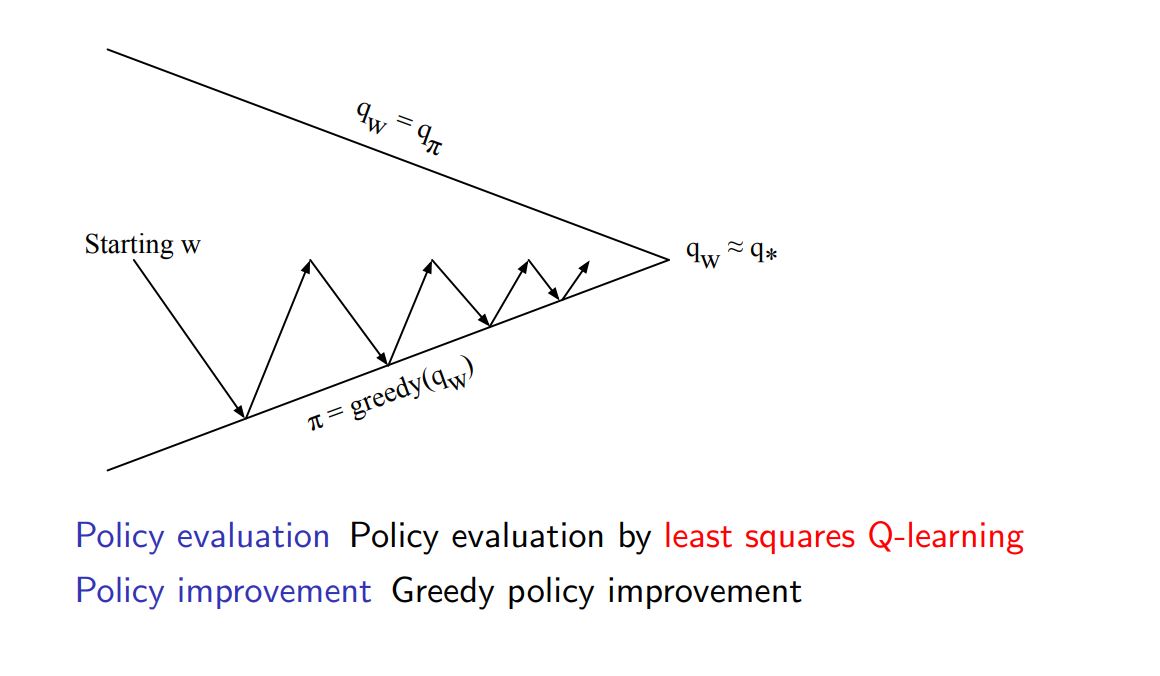
Least Squares Policy Iteration(LSPI) ¶
Least Squares Action-Value Function Approximation ¶

Least Squares Control ¶

Least Squares Q-Learning ¶

Least Squares Policy Iteration(LSPI) Algorithm ¶
