Policy Gradient Methods ¶
Table of Content¶
1) Introduction: Policy Gradient vs the World, Advantages and Disadvantages
2) REINFORCE: Simplest Policy Gradient Method
3) Actor-Critic Methods
4) Additional Enhancements to Actor-Critic Methods
Introduction ¶
Introduction ¶

Value-Based Vs Policy-Based RL ¶
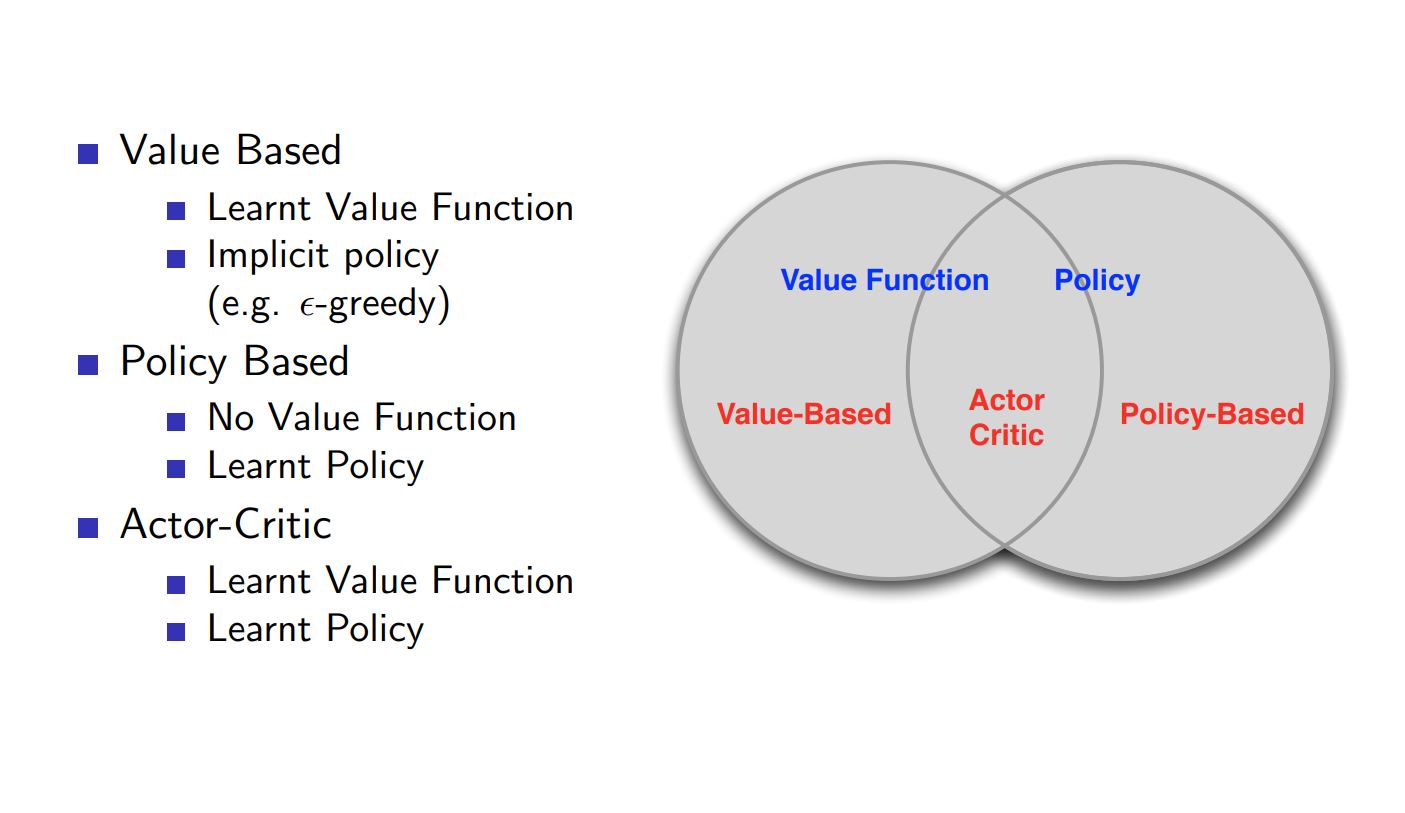
Why Policy-Based RL ¶

Can Learning Policy be easier than Learning Values of states? ¶
- The policy may be a simpler function to approximate.
- This is the simplest advantage that policy parameterization may have over action-value parameterization.
Why?
- Problems vary in the complexity of their policies and action-value functions.
- For some, the action-value function is simpler and thus easier to approximate.
- For others, the policy is simpler.
In the latter case a policy-based method will typically be faster to learn and yield a superior asymptotic policy.
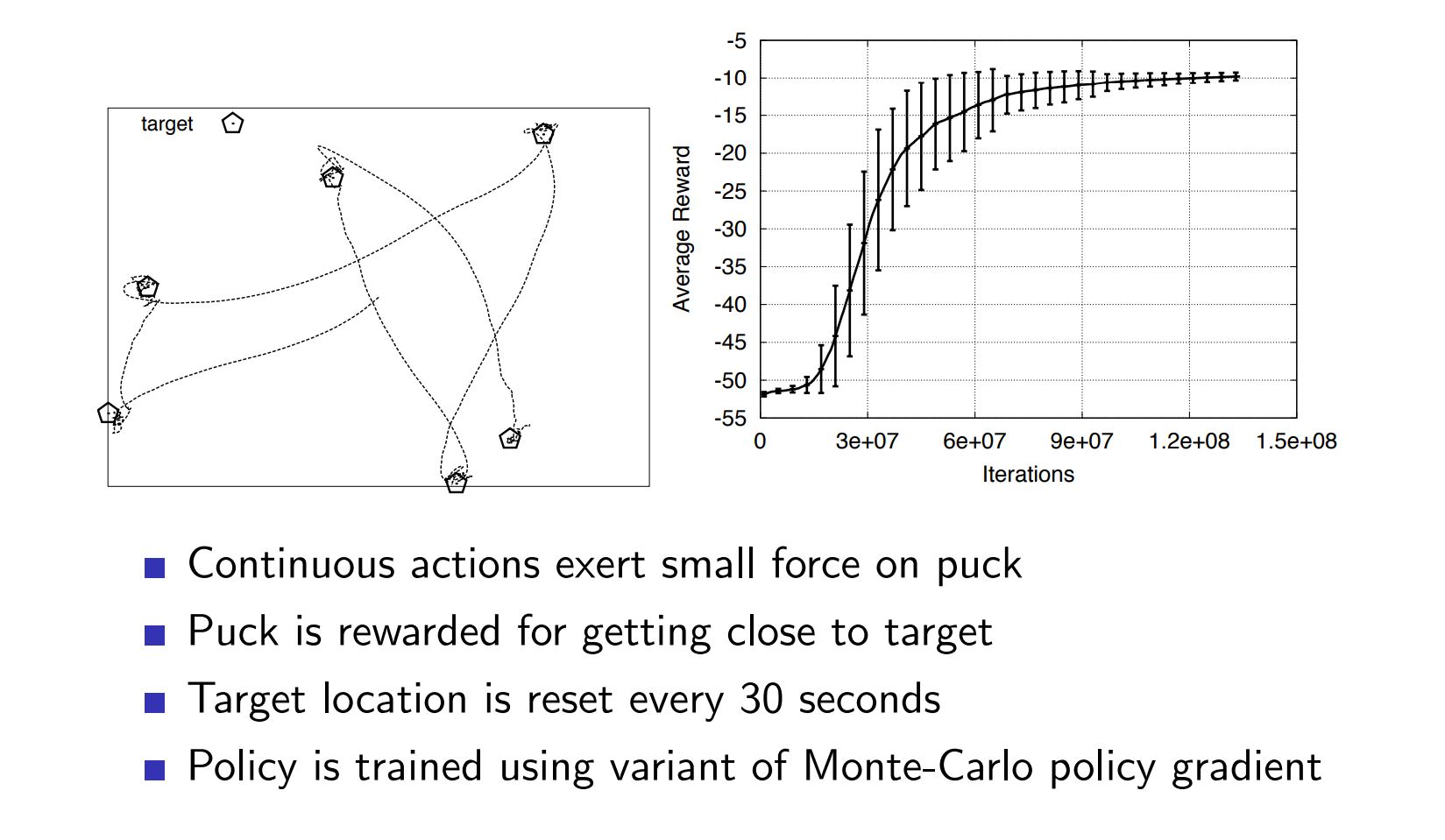
Example: In Robotics Tasks with continuous Action space.
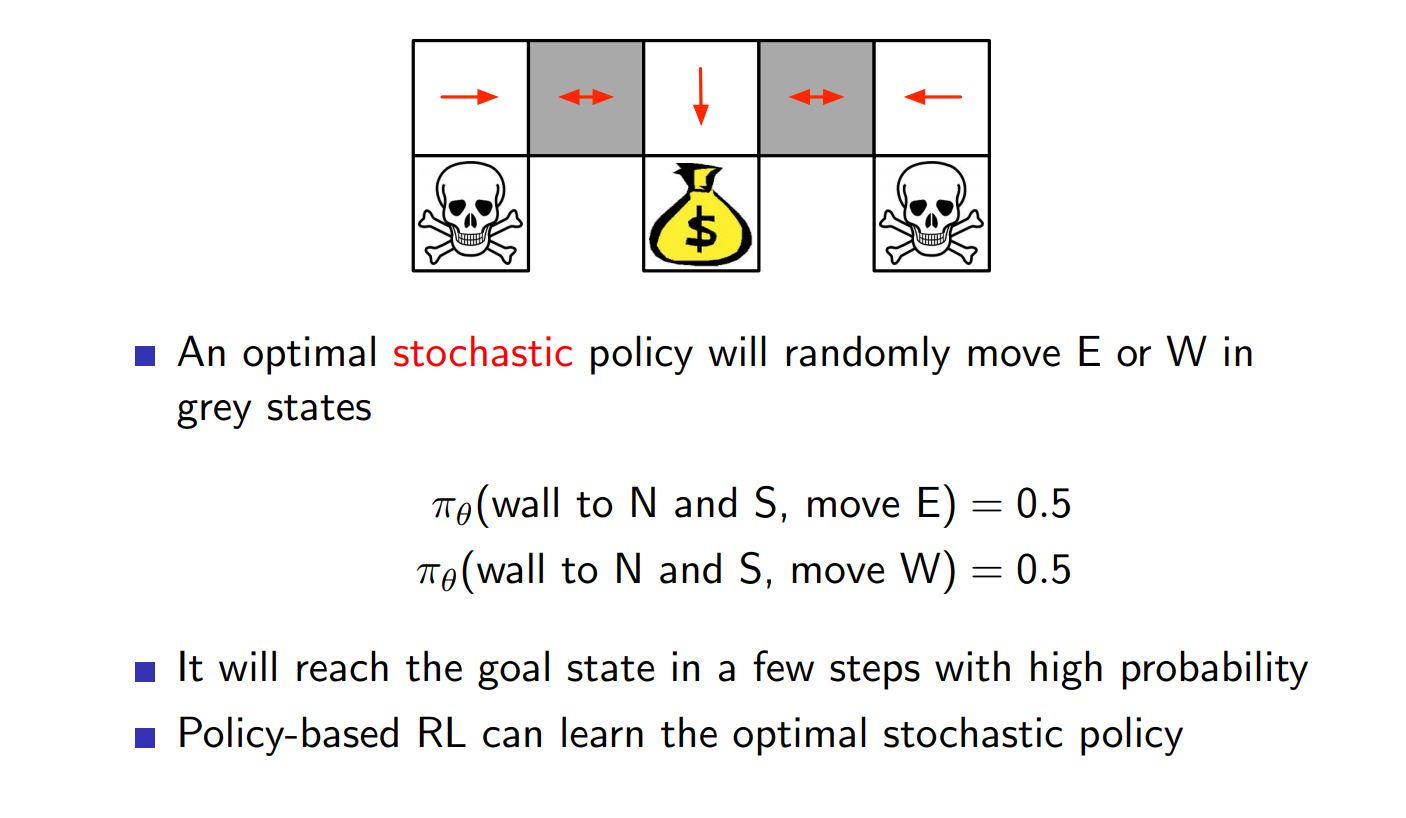
Example of Stochastic Optimal Policy ¶

Example of Stochastic Optimal Policy ¶

Example of Stochastic Optimal Policy ¶
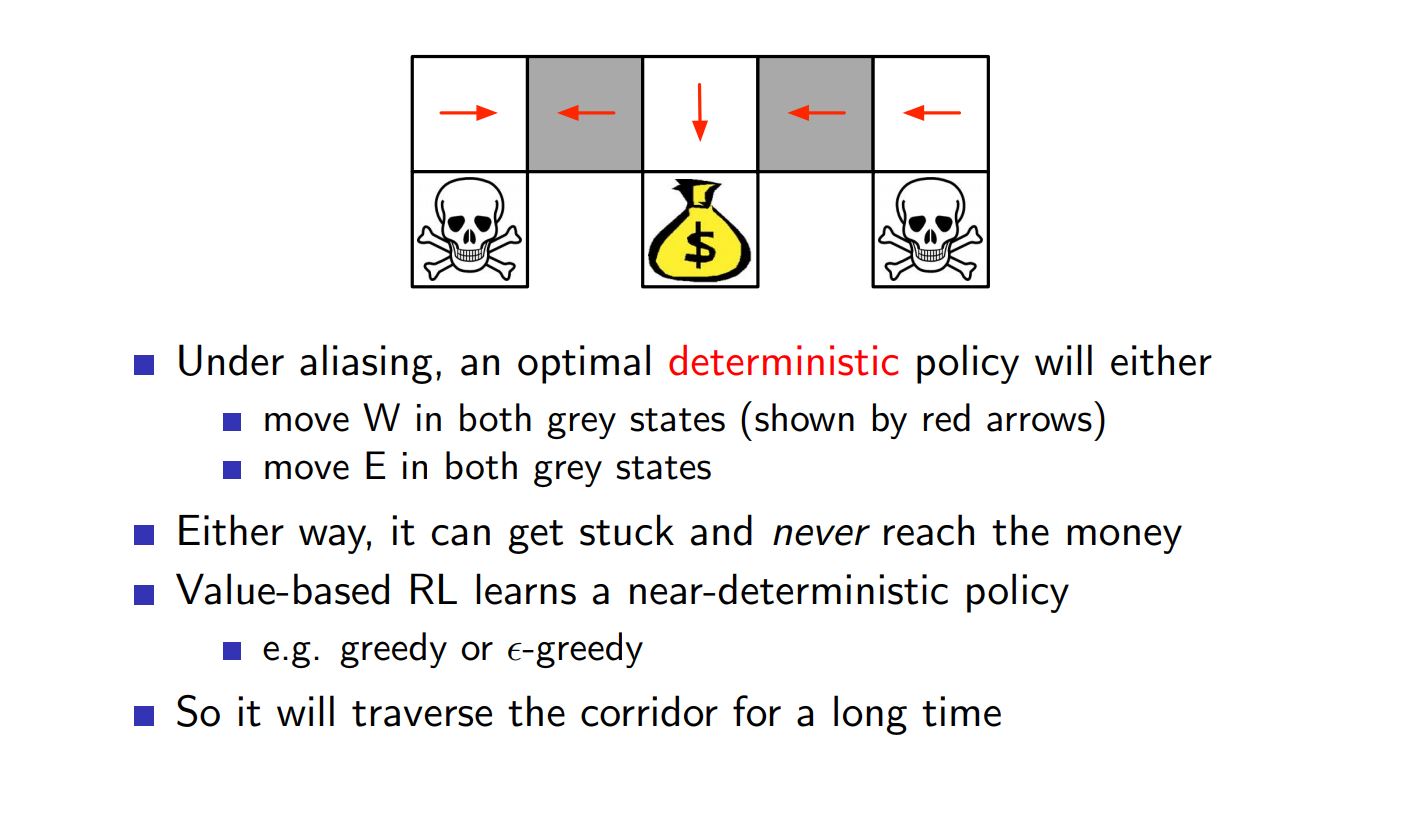
Example of Stochastic Optimal Policy ¶
Why not use softmax of Action-Values for stochastic Policies?¶
- This alone would not approach determinism if and when required.
- The action-value estimates would differ by a finite amount, translating to specific probabilities other than 0 and 1.
- If softmax + Temprature Paramenter T: T could be reduced over time to approach determinism.
- However, in practice it would be difficult to choose the reduction schedule, or even the initial temperature, without more knowledge of the true action values.
- Whereas, Policy gradient is driven to produce the optimal stochastic policy.
- If the optimal policy is deterministic, then the preferences of the optimal actions will be driven infinitely higher than all suboptimal actions
REINFORCE: Simplest Policy Gradient Method ¶
Quality Measure of Policy ¶

Policy Optimisation ¶

Gradient Ascent ¶
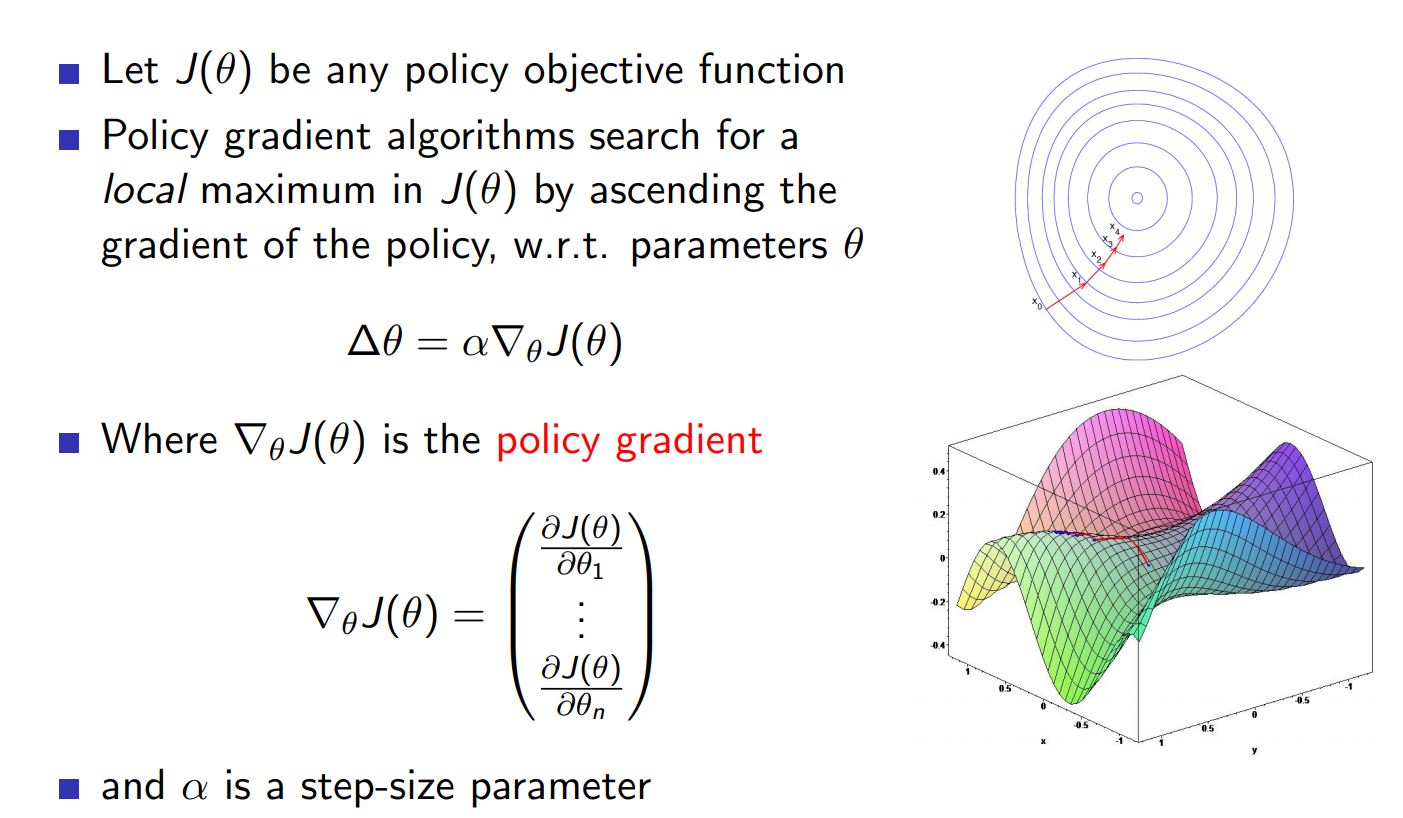
Gradient Ascent - FDM ¶

Analytic Gradient Ascent ¶

Example- Softmax Policy ¶

Example- Gaussian Policy ¶

One-step MDP ¶

Policy Gradient Theorem ¶

Policy Gradient Theorem-Proof ¶

Monte-Carlo Policy Gradient (REINFORCE) ¶

REINFORCE with Baseline ¶
- REINFORCE has good theoretical convergence properties.
- The expected update over an episode is in the same direction as the performance gradient.
- This assures:
- An improvement in expected performance for sufficiently small $\alpha$, and
- Convergence to a local optimum under standard stochastic approximation conditions.
- However,
- Monte Carlo method REINFORCE may be of high variance, and thus
- slow to learn.
Can we reduce the variance somehow?
REINFORCE with Baseline ¶
- The derivative of the quality $\eta(\theta)$ of policy network can be written as
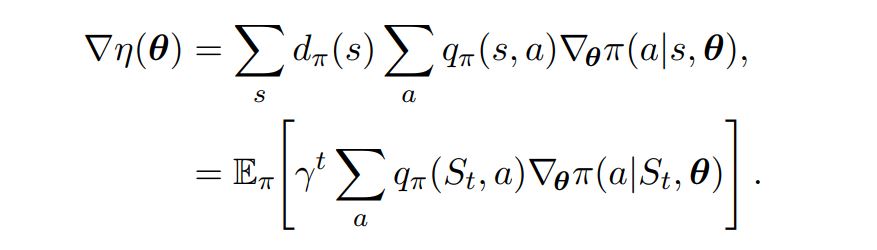
- Instead of using the Rewards/Action Vaules generated directly, we first compare it with a baseline:
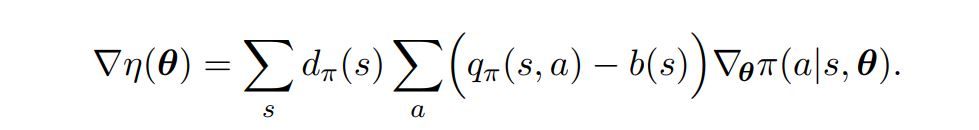
- The baseline can be any function, even a random variable,
- Only Condition: Should not vary with action $a$;
- Any guesses why?
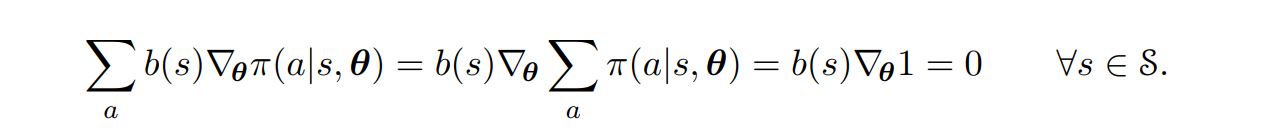
- Finally the Update equation becomes:
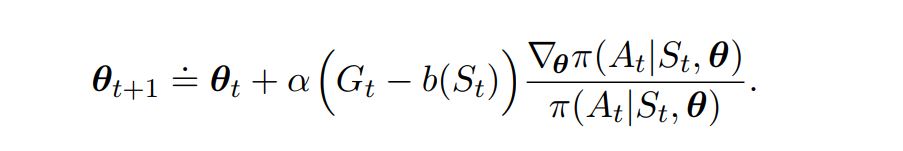
Actor Critic Methods ¶
Reducing Variance Using a Critic ¶

Estimating the Action-Value Function ¶

Action Value Actor Critic ¶

Bias In Actor-Critic Algorithm ¶

Compatible Function Approximation ¶

Compatible Function Approximation- Proof ¶

Additional Enhancements to Actor Critic ¶
Actor Critic with Baseline ¶

Estimating the Advantage Function ¶

Estimating the Advantage Function ¶

Critics at different Time-Scales ¶
Actors at different Time-Scale ¶

Policy Gradient with Eligibility Traces ¶

Policy Gradient with Eligibility Traces ¶

Summary ¶
