Contents ¶
- RL: Formal Definition
- RL vs Supervised Learning vs Unsupervised learning
- Important RL Perspectives
- Goal (Reward Hypothesis)
- Sequential Decision Making Problem
- Interaction between Agent and Environment
- Components of RL Agent
- RL Problems: Learning and Planning
- Prediction and Control
RL Formal Definition ¶
"Reinforcement learning is the problem of getting an agent to act in the world so as to maximize its rewards. For example, consider teaching a dog a new trick: you cannot tell it what to do, but you can reward/punish it if it does the right/wrong thing. It has to figure out what it did that made it get the reward/punishment, which is known as the credit assignment problem."

RL vs Supervised Learning vs Unsupervised Learning ¶
Supervised Learning¶
1) A human builds a classifier based on input and output data
2) That classifier is trained with a training set of data
3) That classifier is tested with a test set of data
4) Deployment if the output is satisfactory
To be used when, "I know how to classify this data, I just need you(the classifier) to sort it."
Point of method: To class labels or to produce real numbers
Unsupervised Learning¶
1) A human builds an algorithm based on input data
2) That algorithm is tested with a test set of data (in which the algorithm creates the classifier)
3) Deployment if the classifier is satisfactory
To be used when, "I have no idea how to classify this data, can you(the algorithm) create a classifier for me?" Point of method: To class labels or to predict
Reinforcement Learning¶
1) A human builds an algorithm based on input data
2) That algorithm presents a state dependent on the input data in which a user rewards or punishes the algorithm via the action the algorithm took, this continues over time
3) That algorithm learns from the reward/punishment and updates itself, this continues
4) It's always in production, it needs to learn real data to be able to present actions from states
To be used when, "I have no idea how to classify this data, can you classify this data and I'll give you a reward if it's correct or I'll punish you if it's not."
RL vs Supervised Learning¶
- Training Examples
- Supervised Learning: Training Examples of the formNo training examples from a knowledgeable external supervisor (situation together with a label).
- RL: No such training examples.
- Objective Functions
- Supervised Learning: Aim is to extrapolate, or generalize so that it acts correctly in situations not present in the training set.
- In RL, it is often impractical to obtain examples of desired behavior that are both correct and representative of all the situations and an agent must be able to learn from its own experience.
RL vs Unsupervised Learning¶
- Unsupervised Learning is about finding structure hidden in collections of unlabeled data.
- Uncovering structure in an agent’s experience can certainly be useful in reinforcement learning, but by itself does not address the reinforcement learning agent’s problem of maximizing a reward signal.
Examples of RL¶
- Fly stunt manoeuvres in a helicopter
- Defeat the world champion at Backgammon
- Manage an investment portfolio
- Control a power station
- Make a humanoid robot walk
- Play many different Atari games better than humans
Important RL Perspectives ¶
Goal of RL (Reward Hypothesis)¶

Reward Examples¶
- stunt manoeuvres in a helicopter
- +ve reward for following desired trajectory
- −ve reward for crashing
- Defeat the world champion at Backgammon
- +/−ve reward for winning/losing a game
- Manage an investment portfolio
- +ve reward for each dollar in bank
- Control a power station
- +ve reward for producing power
- −ve reward for exceeding safety thresholds
- Make a humanoid robot walk
- +ve reward for forward motion
- −ve reward for falling over
- Play many different Atari games better than humans
- +/−ve reward for increasing/decreasing score
Sequential Decision Making Problem¶
- Goal: select actions to maximise total future reward
- Actions may have long term consequences
- Reward may be delayed
- It may be better to sacrifice immediate reward to gain more long-term reward
- Examples:
- A financial investment (may take months to mature)
- Refuelling a helicopter (might prevent a crash in several hours)
- Blocking opponent moves (might help winning chances many moves from now)
Interaction between Agent and Environment¶
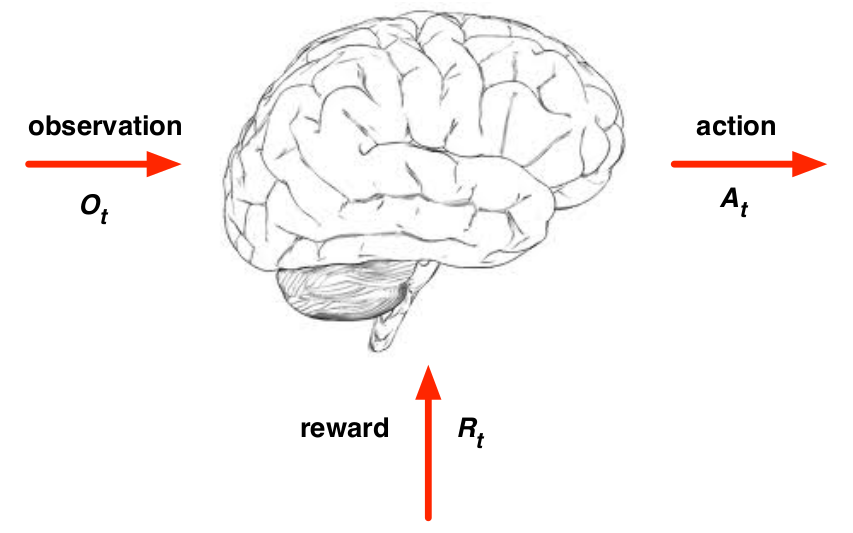
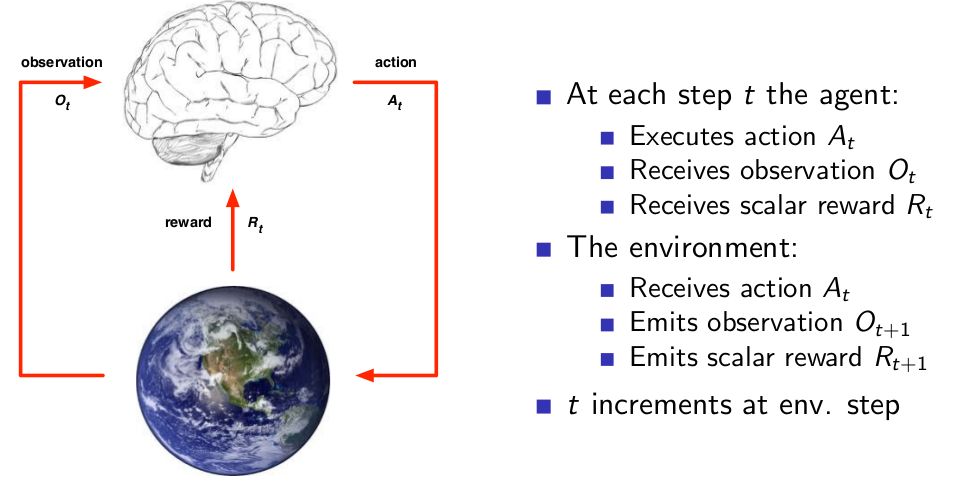
Interaction between Agent and Environment¶
History and State¶

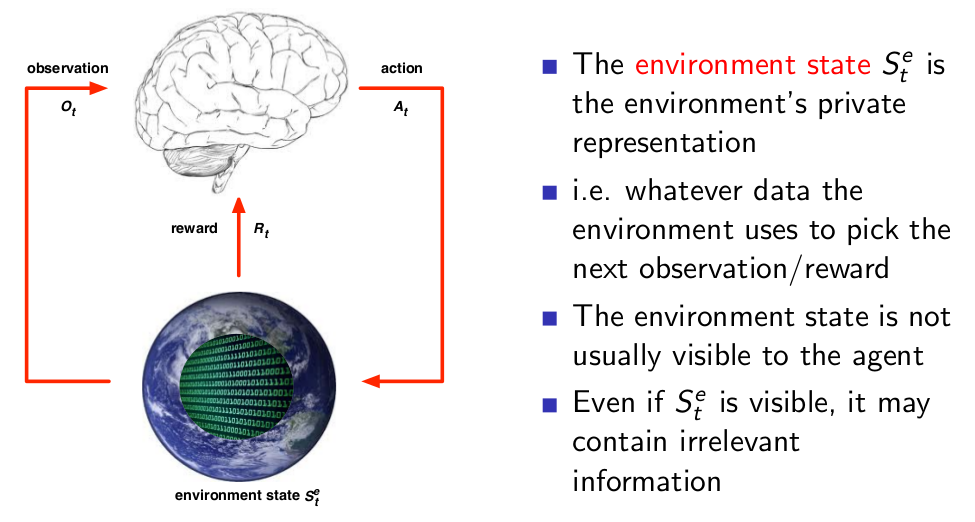
Environment State¶
Agent State¶
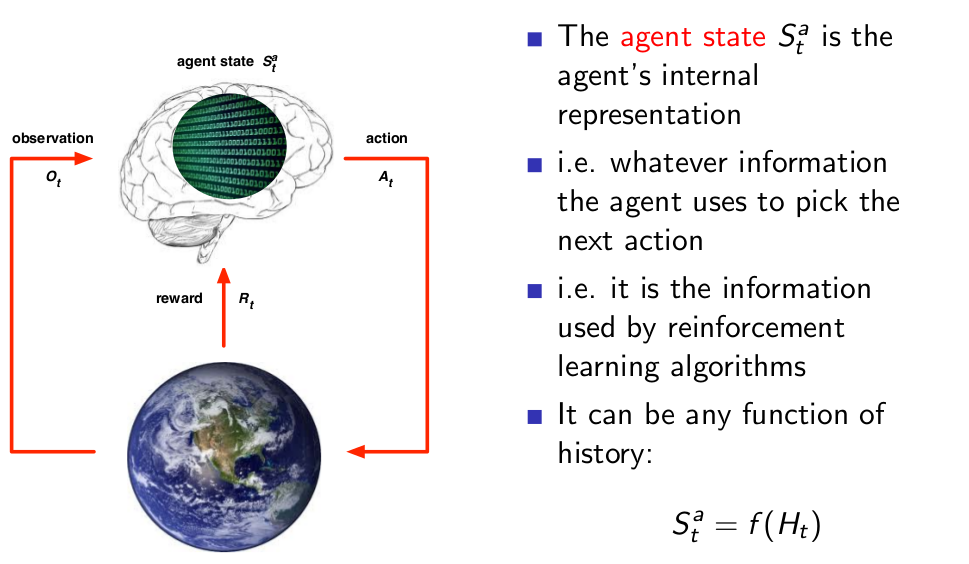
Information State¶

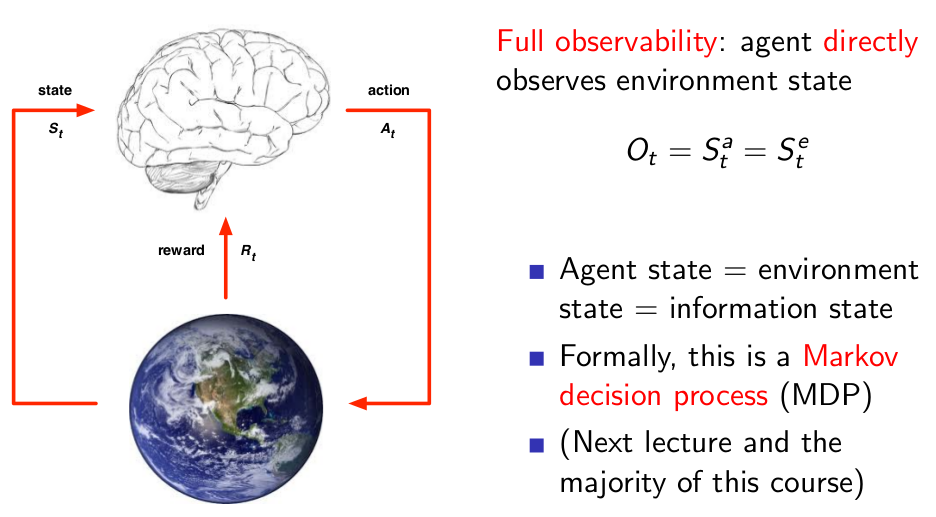
Fully Observable Environment¶
Partially Observable Environment¶

Major Components of a RL Agent¶
An RL agent may include one or more of these components:
- Policy: agent’s behaviour function
- Value function: how good is each state and/or action
- Model: agent’s representation of the environment
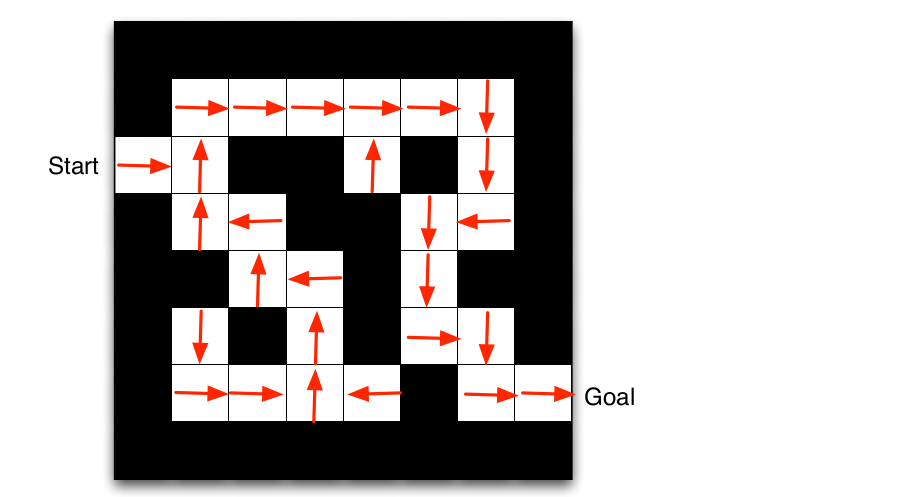
Policy¶
- A policy is the agent’s behaviour
- It is a map from state to action, e.g.
- Deterministic policy: $a = π(s)$
- Stochastic policy: $π(a|s) = P[A_t = a|S_t = s]$
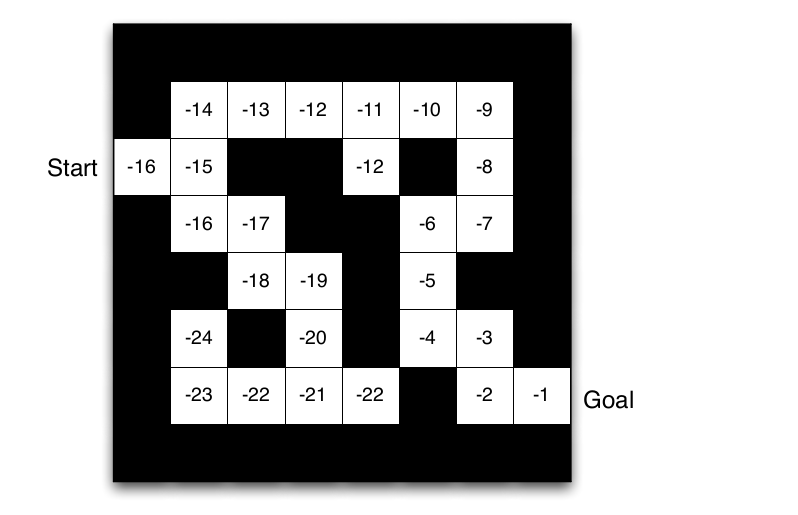
Value function¶
- Value function is a prediction of future reward
- Used to evaluate the goodness/badness of states
- And therefore to select between actions, e.g. $$v_π(s) = E_π[R _{t+1} + γ*R_{t+2} + γ^{2}*R_{t+3} + ... | S_t = s]$$
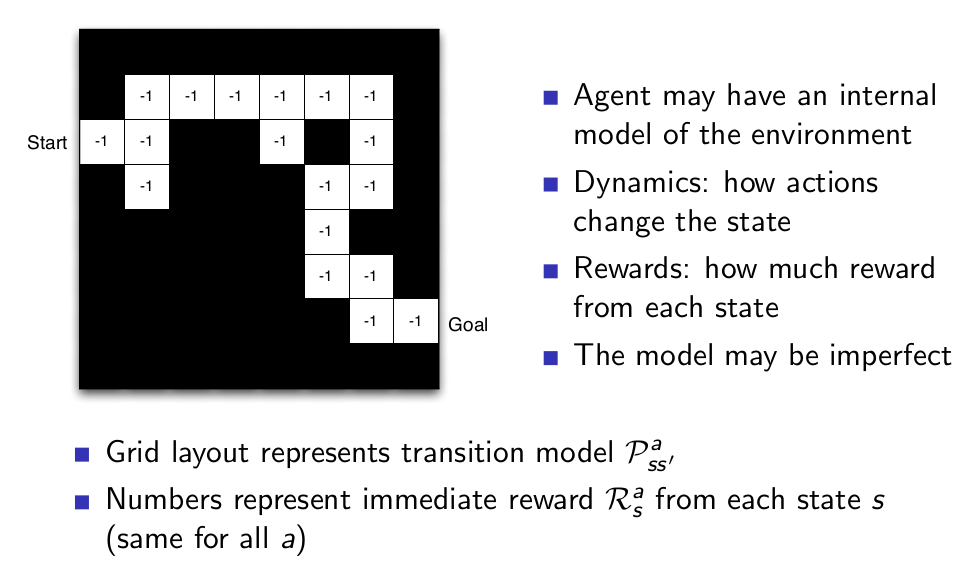
Model¶
- A model predicts what the environment will do next
- Transitions: P predicts the next state (i.e. dynamics)
- Rewards: R predicts the next (immediate) reward, e.g. $$ P_{ss'} = P[S_{t+1} = s' | S_t = s, A_t = a]$$ $$ R^{a}_{s} = E[R_{t+1} | S_t = s, A_t = a]$$
Maze Example¶

Maze Example: Value Function¶
Maze Example: Model¶
Learning and Planning¶
Two fundamental problems in sequential decision making:
- Reinforcement Learning:
- The environment is initially unknown
- The agent interacts with the environment
- The agent improves its policy
- Planning:
- A model of the environment is known
- The agent performs computations with its model (without any external interaction)
- The agent improves its policy a.k.a. deliberation, reasoning, introspection, pondering, thought, search
Exploration and Exploitation¶
- Reinforcement learning is like trial-and-error learning
- The agent should discover a good policy,
- From its experiences of the environment,
- Without losing too much reward along the way
- Exploration finds more information about the environment
- Exploitation exploits known information to maximise reward
- It is usually important to explore as well as exploit (In Detail => Chapter 2).
Examples of Explortion and Exploitation¶
- Restaurant Selection
- Exploitation Go to your favourite restaurant
- Exploration Try a new restaurant
- Online Banner Advertisements
- Exploitation Show the most successful advert
- Exploration Show a different advert
- Oil Drilling
- Exploitation Drill at the best known location
- Exploration Drill at a new location
- Game Playing
- Exploitation Play the move you believe is best
- Exploration Play an experimental move
Summary¶
- We got introduced to the basic terminologies of RL.
- We got an intuition behind how an RL agent can solve problems.