Contents ¶
- Recap: What is Dynamic Programming?
- Planning by DP in MDP
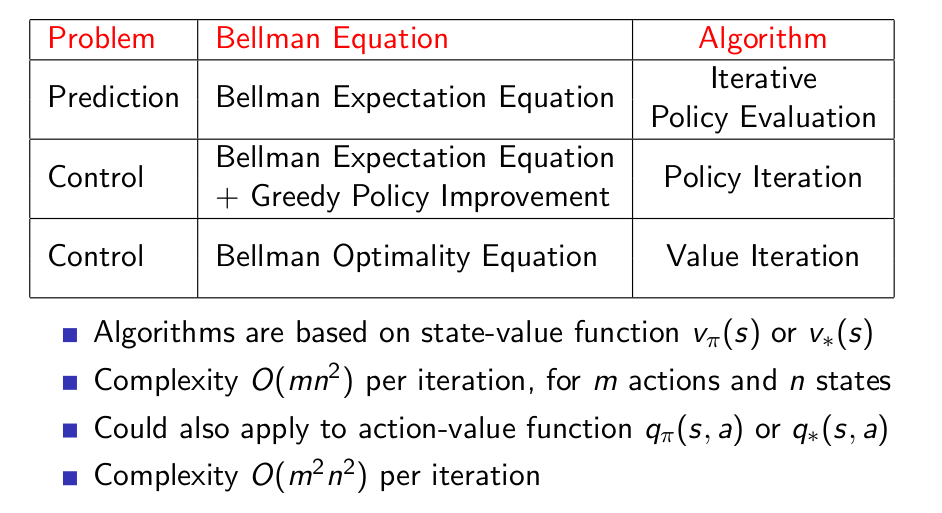
- Prediction
- Iterative Policy Evaluation
- Policy Improvement Theorem
- Example: Gridworld (Policy Evaluation and Policy Improvement)
- Control
- Policy Iteration
- Value Iteration
- Synchronous vs Asynchronous Dynamic Programming Algorithms
- Full-Width Backups/Sample Backups
Recap: What is Dynamic Programming ¶
Recap: What is Dynamic Programming ¶
Dynamic: sequential or temporal component to the problem
Programming: optimising a “program”, i.e. a policy
- A method for solving complex problems
- By breaking them down into subproblems
- Solve the subproblems
- Combine solutions to subproblems
Requirements for Dynamic Programming¶
Dynamic Programming is a very general solution method for problems which have two properties:
- Optimal substructure
- Principle of optimality applies
- Optimal solution can be decomposed into subproblems
- Overlapping subproblems
- Subproblems recur many times
- Solutions can be cached and reused
Examples of DP problems:¶
#### Travelling salesman problem:
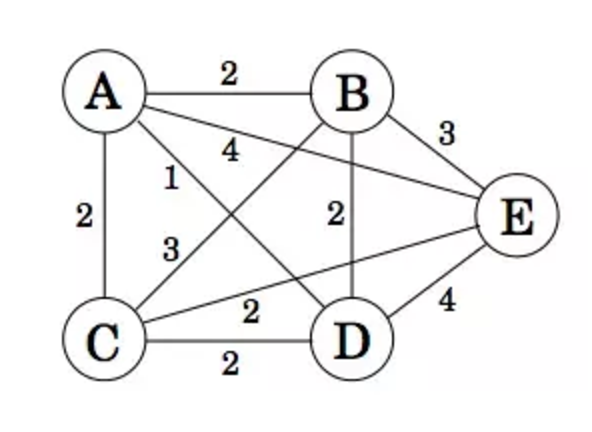
- Optimal substructure?
- Overlapping subproblems?
- Algorithms like Dijsktra's algorithm for solving the problem.
- ### Other Use Cases:
- String Sequence alignment
- Scheduling
DP in Markov Decision Process¶
Markov decision processes satisfy both properties
- Bellman equation gives recursive decomposition
- Value function stores and reuses solutions
Dynamic programming (DP) in MDP world refers to a collection of algorithms that can be used to compute optimal policies
- given a perfect model of the environment as a Markov decision process (MDP).
- Essential foundation for the understanding of the other RL methods
- All other RL methods can be viewed as attempts to achieve much the same effect as DP, only with
- less computation and
- without assuming a perfect model of the environment.
Assumption:¶
We assume that the environment is a finite MDP:
- Finite Set of States
- Finite Set of Actions
- Finite Set of Rewards
DP possible in Continuous Spaces as well, but more complex.(Will be seen in future Chapters)
The key idea of DP, and of reinforcement learning generally, is the use of value functions to organize and structure the search for good policies. ¶
Planning by DP in MDP ¶
- Dynamic programming assumes full knowledge of the MDP
- It is used for planning in an MDP
- For prediction:
- Input: MDP $< S, A, P, R, γ>$ and policy $π$
- Output: value function $v_π$
- Or for control:
- Input: MDP $
- Output: optimal value function $v_∗$ and optimal policy $π_∗$
- Input: MDP $
Iterative Policy Evaluation ¶

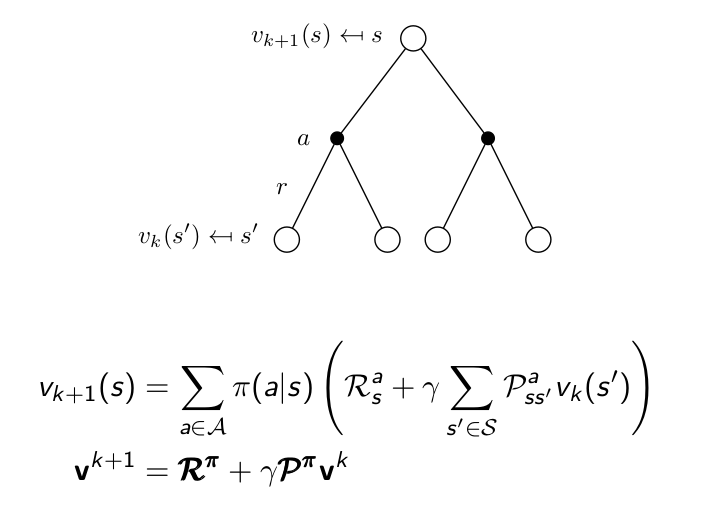
Pseudocode: Policy Evaluation¶

Policy Improvement ¶
Policy Improvement Theorem¶
Let $\pi$ and $\pi'$ be any pair of deterministic policies such that, for all s $\epsilon$ S, $$q_\pi(s,\pi'(s)) \geq v_{\pi}(s)$$ Then the policy $ \pi '$ must be as good as, or better than $\pi$. That is it must obtain greater or equal expected return from all states s $\epsilon$ S: $$v_{\pi'}(s) \geq v_{\pi}(s)$$


Example: Gridworld (Policy Evaluation and Policy Improvement) ¶

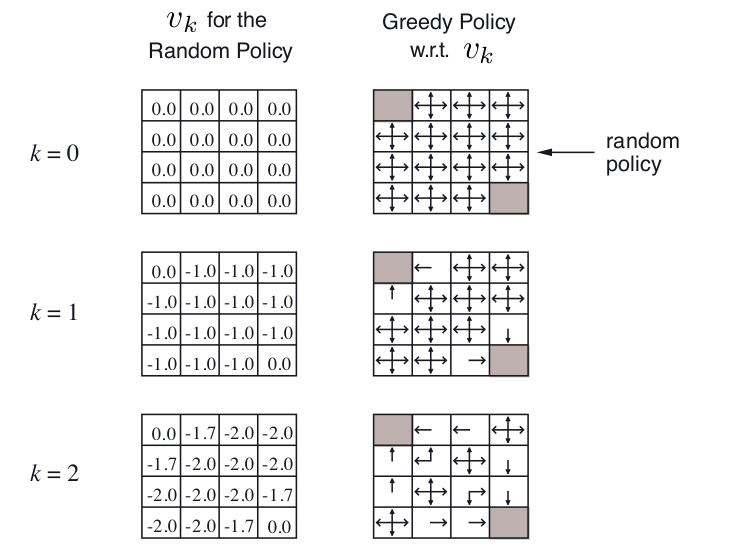
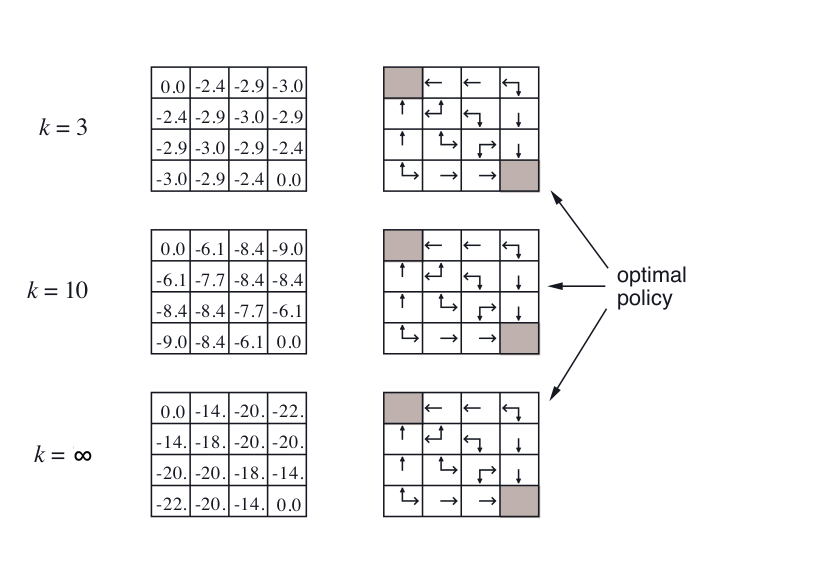
Policy Iteration ¶
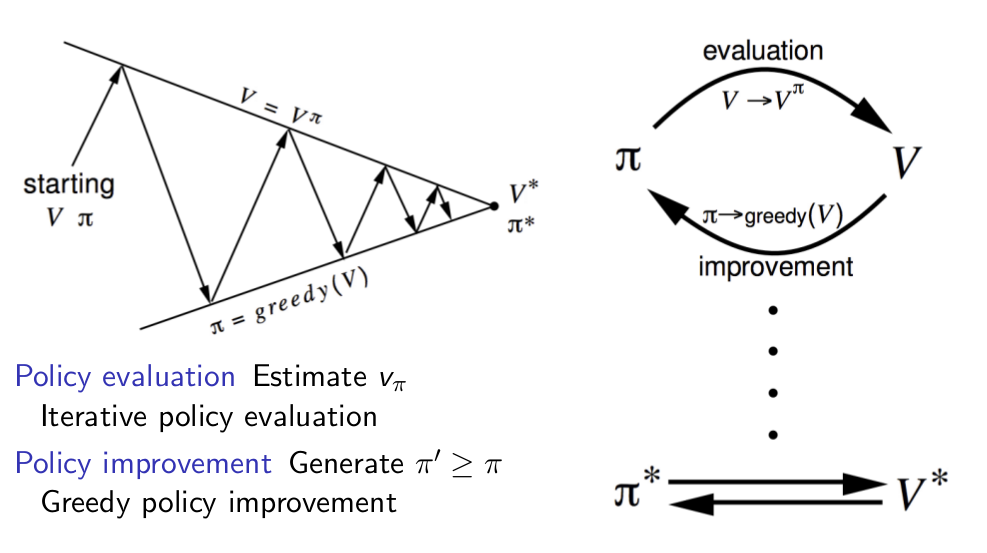
Pseudocode: Policy Iteration¶

Modified Policy Iteration¶
- Does policy evaluation need to converge to $v_π$ ?
- Or should we introduce a stopping condition e.g. $\epsilon$-convergence of value function
- Or simply stop after k iterations of iterative policy evaluation?
- For example, in the small gridworld k = 3 was sufficient to achieve optimal policy
- Why not update policy every iteration? i.e. stop after k = 1
- This is equivalent to value iteration (next section)
Generalised Policy Iteration¶
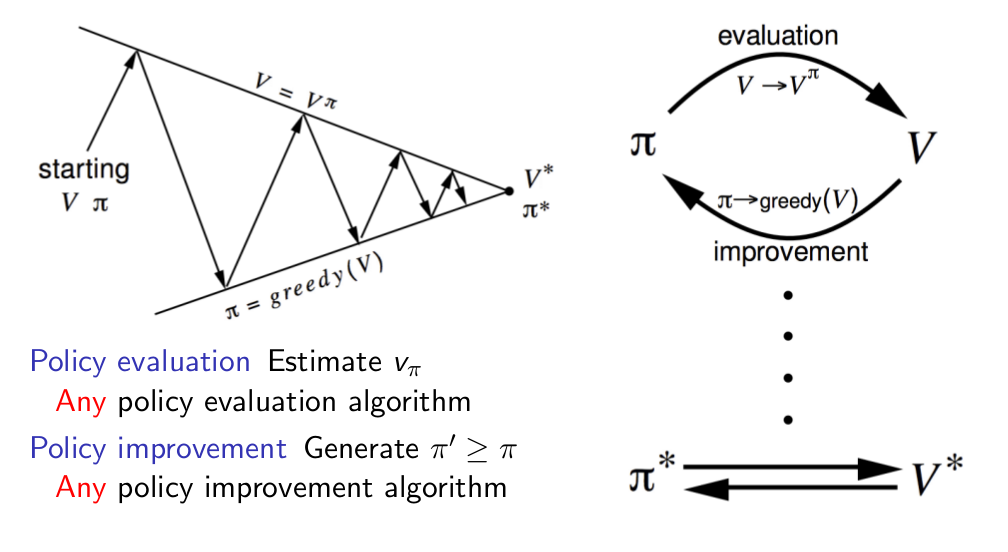
Value Iteration ¶
Principle of Optimality¶
Any optimal policy can be subdivided into two components:
- An optimal first action $A_∗$
- Followed by an optimal policy from successor state S'

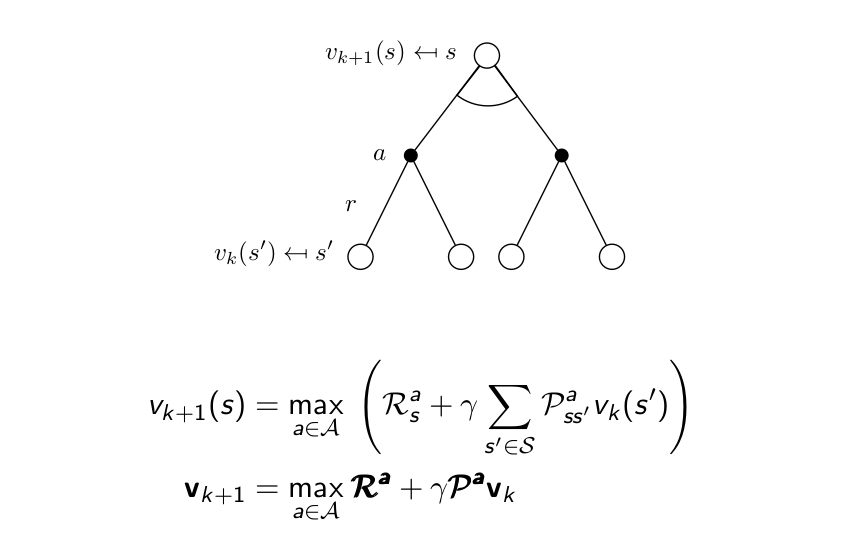
Deterministic Value Iteration¶

Pseudocode: Value Iteration¶

Example: Shortest Path¶
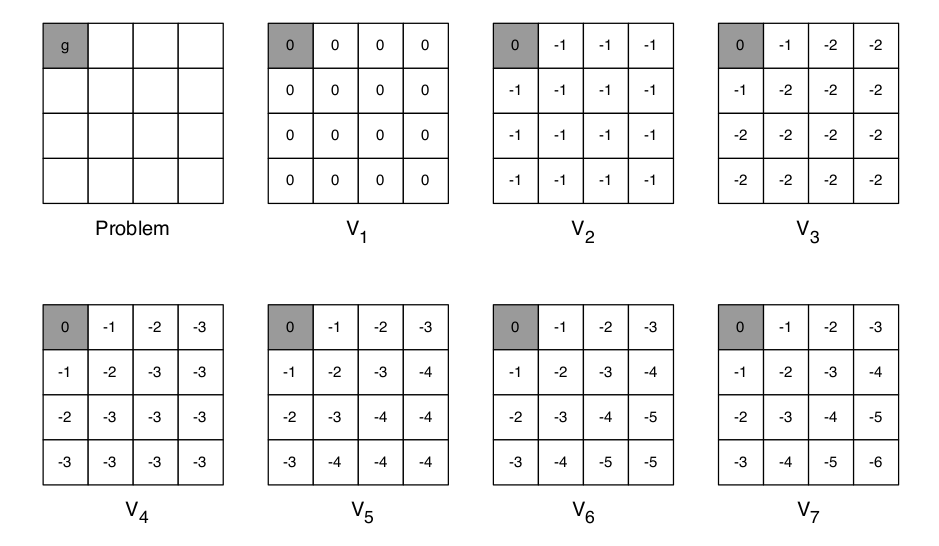


Synchronous Dynamic Programming Algorithm ¶
Problems with Synchronous DP¶
- Involve operations over the entire state set of the MDP:
- Require sweeps of the state set.
- Even a single sweep can be prohibitively expensive.
- Game of backgammon has over $10^{20}$ states.
- value iteration backup at a million states per second ==> a thousand years to complete a single sweep.
- Algorithm gets locked into a long sweep before it can make progress improving a policy.
- take advantage of latest updates to backups so as to improve the algorithm’s rate of progress.
- Skip backing up some states entirely if they are not relevant to optimal behavior.
- Update States related to the optimal behaviour only.
Asynchronous Dynamic Programming Methods ¶
- DP methods described so far used synchronous backups
- i.e. all states are backed up in parallel
- Asynchronous DP backs up states individually, in any order
- For each selected state, apply the appropriate backup
- Can significantly reduce computation
- Guaranteed to converge if all states continue to be selected
Three simple ideas for asynchronous dynamic programming:
- In-place dynamic programming
- Prioritised sweeping
- Real-time dynamic programming
In Place Dynamic Programming¶

Prioritised Sweeping¶

Real-time Dynamic Programming¶

Full-Width Backup/ Sample Backup ¶
Full-Width Backup¶

Sample Backup¶

Summary ¶
Summary¶
- Familiarity with the basic ideas and algorithms of dynamic programming in solving finite MDPs.
- Policy Evaluation
- Policy Improvement
- Two Control Algorithms with DP
- Policy Iteration
- Value Iteration
- Synchronous Vs Asynchronous Algorithms for implementing DP in RL
- In-place dynamic programming, Prioritised sweeping, Real-time dynamic programming
Extra Material ¶
1) Proof of convergence for value iteration and policy iteration.
2) Examples of Asynchronous DP in action
Convergence of presented algorithms ¶
1) How do we know that value iteration converges to the optimal values for the given policy $v_*$?
2) Or that iterative policy evaluation converges to $v_\pi$?
3) Is the solution unique?
Basic Components of Proof:¶
- Value Function Space
- the vector space $V$ over value functions
- There are |S| dimensions
- Each point in this space fully specifies a value function v(s)
- Value Function $\infty$-Norm
- distance between state-value functions $u$ and $v$ by the $\infty$-norm
- $$ ||u-v ||_{\infty} = max_{s \in S}|u(s) - v(s)|$$
Basic Components of Proof:¶
- Contraction Mapping
- A contraction mapping, on a metric space $(M,d)$ is a function $f$ from $M$ to itself, with the property that there is some nonnegative real number $0 \leq k \le 1$ such that for all $x$ and $y$ in $M$,
- $$ d(f(x),f(y)) \leq k d(x,y) $$
- Contraction mapping Theorem

Bellman Expectation Backup is a Contraction¶
Bellman Expectation Backup is a Contraction¶

Bellman Optimality Backup is a Contraction¶
Bellman Optimality Backup is a Contraction¶

Hence,¶
- The Bellman expectation operator $T_\pi$ has a unique fixed point.
- $v_\pi$ is a fixed point of $T\pi$ (by Bellman expectation equation)
- By contraction mapping theorem,
- Iterative policy evaluation converges on $v_\pi$
- Policy iteration converges on $v_∗$
Similarly,
- The Bellman optimality operator $T_*$ has a unique fixed point.
- $v_∗$ is a fixed point of $T_∗$ (by Bellman optimality equation)
- By contraction mapping theorem,
- Value iteration converges on $v_∗$
Real Life Examples of Asynchronous DP¶
Real Life Examples of Asynchronous DP¶
Asynchronous DP Algorithms outlined previously:
- In-place dynamic programming
- Prioritised sweeping
- Real-time dynamic programming
We will look into one example on how prioritised Sweeping can help improve Policy Evaulations.
Prioritized Sweeping¶

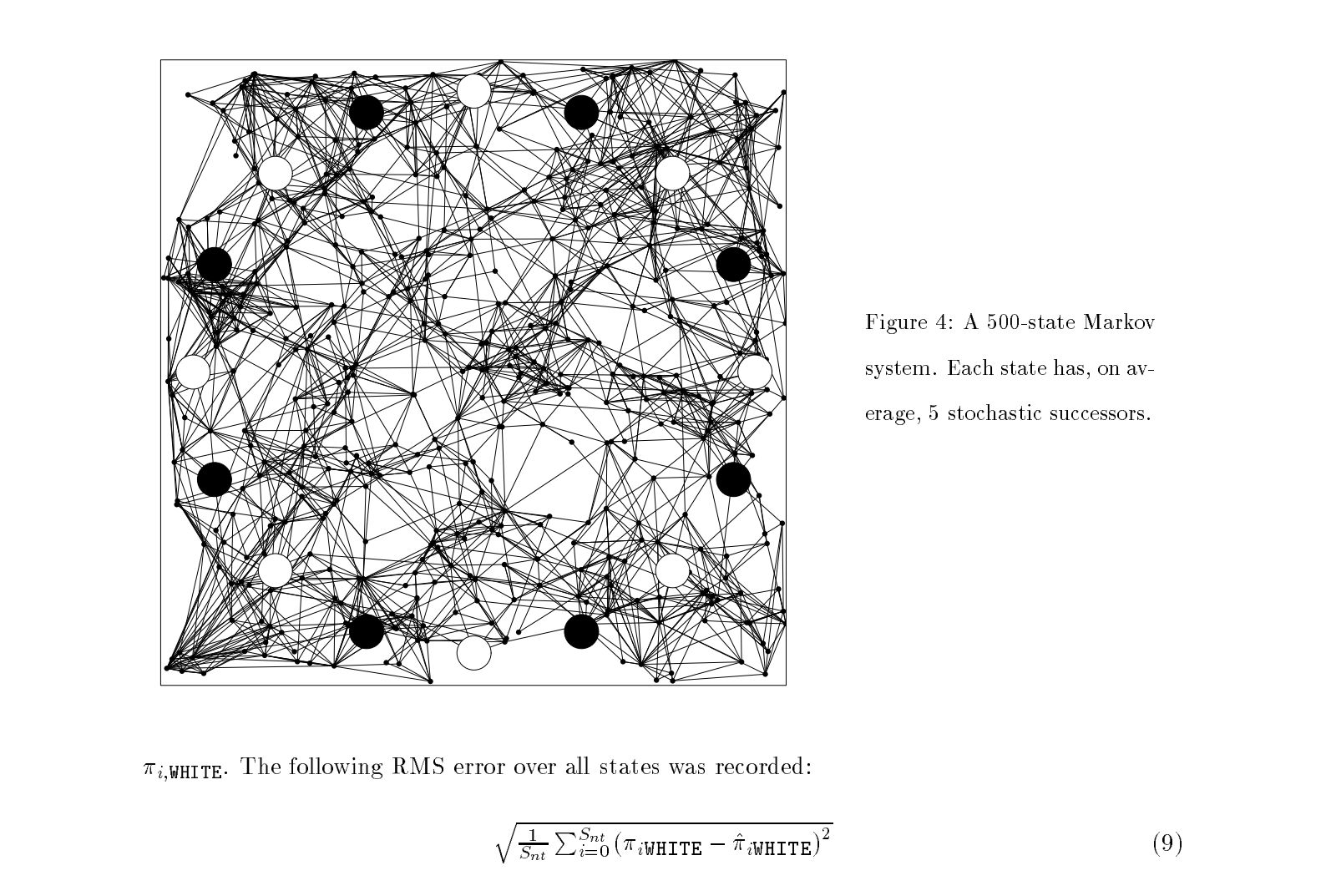
Task¶
- A 500 State MDP
- 16 Terminal States, 8 black and 8 white.
- The prediction problem is to estimate, for every non-terminal state, the long-term probability that it will terminate in a black, rather than a white, circle.
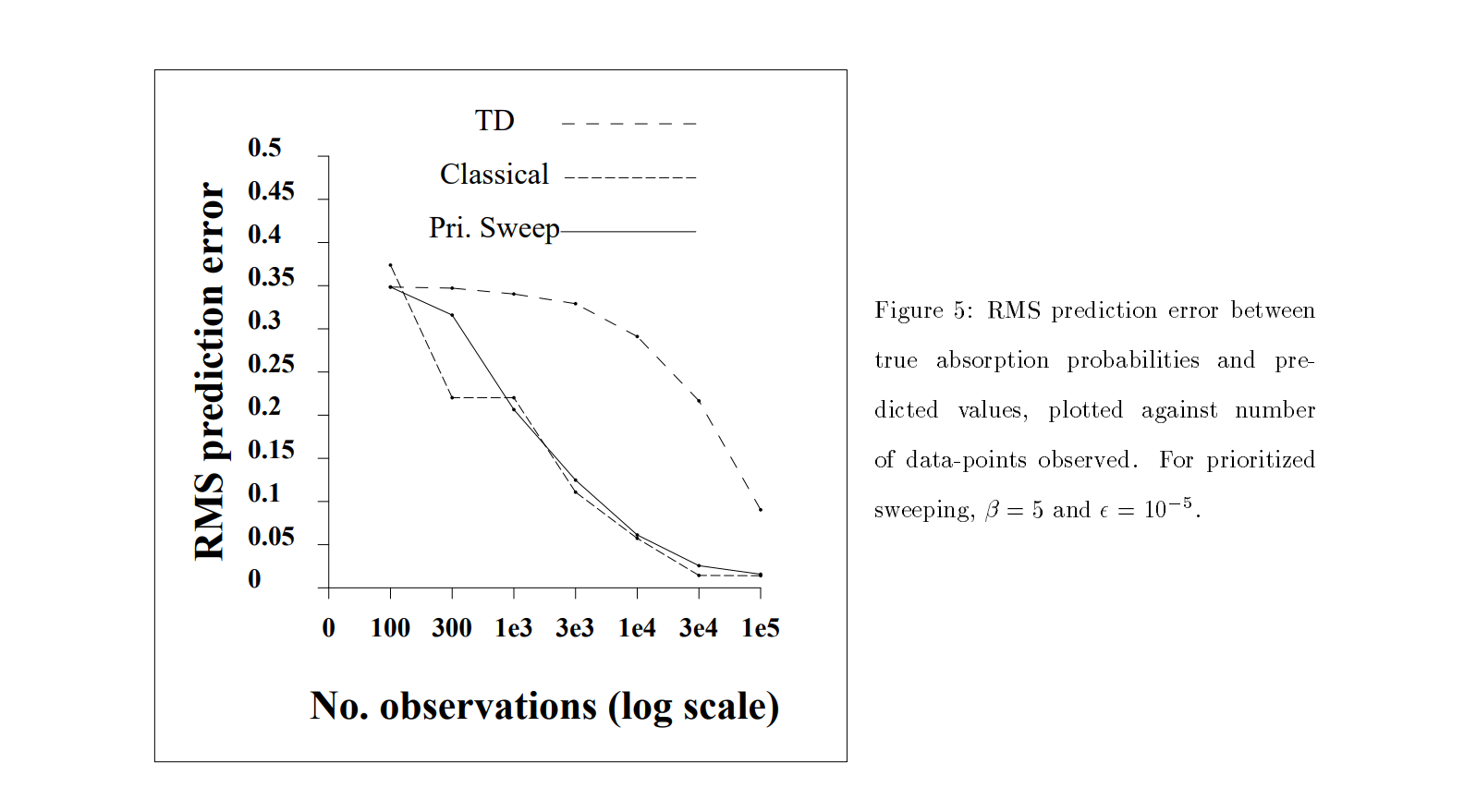
Results¶
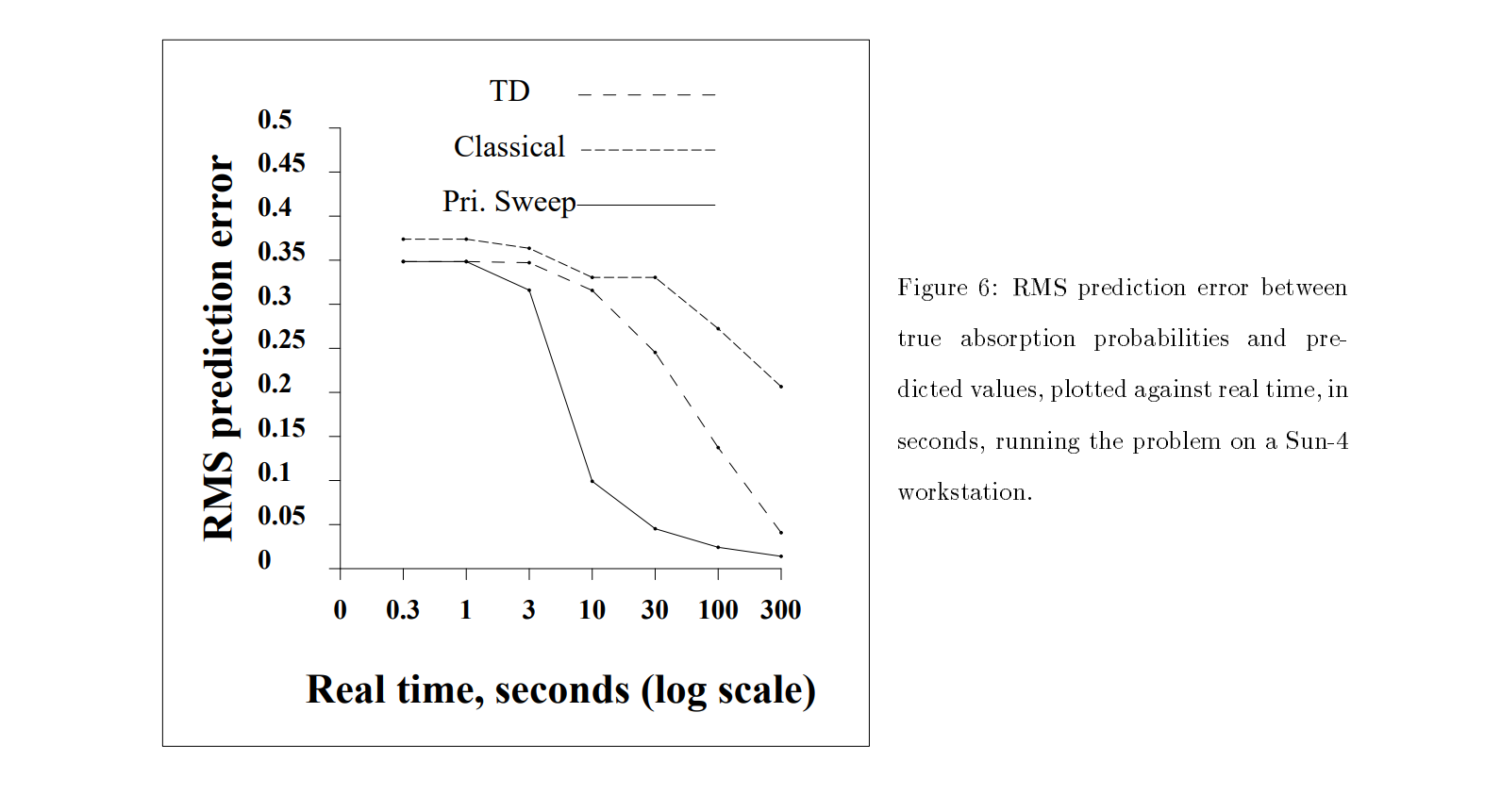
Results¶
Conclusion:¶
- Model-free methods perform well in real time but make weak use of their data.
- Classical methods make good use of their data but are often impractically slow.
- Techniques such as prioritized sweeping are interesting because they may be able to achieve both.
- Example of In-place DP in Tutorial
- An example similar to real-time DP will be covered in Chapter 5.