Active object localization with deep reinforcement learning.
Problem Statement
The aim is to localize objects in scenes, a.k.a Object Detection. To do so, an active detection model is presented which is class-specific. A RL agent is trained such to deform a bounding box using simple transformation actions, with the goal of determining the most specific location of target objects following top-down reasoning. The agent’s performance is evaluated on the Pascal VOC 2007 dataset.
Proposed Model Outcome

RL Components
The problem has been modeled as a Markov Decision Process. Formally, the MDP has a set of actions A, a set of states S, and a reward function R.
- Actions The set of actions A is composed of eight transformations that can be applied to the box and one action to terminate the search process. The set of actions are as follows:

-
State Space The state representation is a tuple (o, h), where o is a feature vector of the observed region, and h is a vector with the history of taken actions.
-
Rewards Let b be the box of an observable region, and g the ground truth box for a target object. The reward function $R_{a}(s,s_{0})$ is granted to the agent when it chooses the action a to move from state s to $s_0$. Each state s has an associated box b that contains the attended region. Then, the reward is as follows:
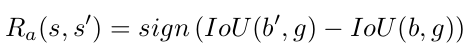
The trigger has a different reward scheme because it leads to a terminal state that does not change the box, and thus, the differential of IoU will always be zero for this action. The reward for the trigger is a thresholding function of IoU as follows:
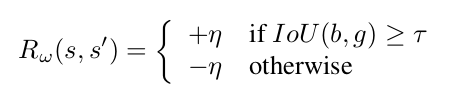
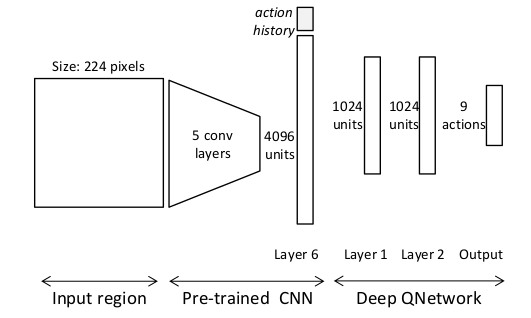
Network Architecture
They use a Q-network that takes as input the state representation discussed.
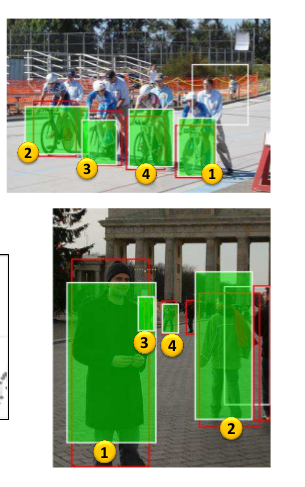
Qualitative Results

Quntitative Results
Comparison with other SOTA methods.

Why use Reinforcement Learing here?
One gets curious as to why we should employ RL, if the results are at most equivalent to SOTA. It is shown that agents guided by the proposed model are able to localize a single instance of an object after analyzing only between 11 and 25 regions in an image, and obtain the best detection results among systems that do not use object proposals for object localization.
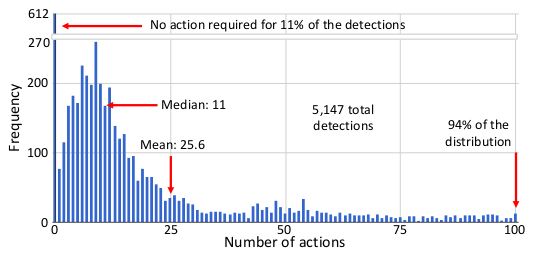
The figure here shows the distribution of detections explicitly marked by the agent as a function of the number of actions required to reach the object. For each action, one region in the image needs to be processed. Most detections can be obtained with about 11 actions only.
Note: All images have been taken from the Paper.