Hierarchical Object Detection with Deep Reinforcement Learning.
Problem Statement
The aim is to localize objects in scenes, a.k.a Object Detection. The key idea is to focus on those parts of the image that contain richer information and zoom on them. A RL agent is trained such that, given an image window, is capable of deciding where to focus the attention among five different predefined region candidates (smaller windows). The agent’s performance is evaluated on the Pascal VOC 2007 dataset.
Proposed Model Outcome
This is he proposed model where th actions involve non-overlapping actions in first case, and overlapping actions in the second.
RL Components
The problem has been modeled as a Markov Decision Process. Formally, the MDP has a set of actions A, a set of states S, and a reward function R.
-
Actions There are two types of possible actions: movement actions that imply a change in the current observed region, and the terminal action to indicate that the object is found and that the search has ended.
-
State Space The state is composed by the descriptor of the current region and a memory vector. The memory vector of the state captures the last 4 actions that the agent has already performed in the search for an object. As the agent is learning a refinement of a bounding box, a memory vector that encodes the state of this refinement procedure is useful to stabilize the search trajectories.
-
Rewards Let b be the box of an observable region, and g the ground truth box for a target object. The reward function $R_{a}(s,s_{0})$ is granted to the agent when it chooses the action a to move from state s to $s_0$. Each state s has an associated box b that contains the attended region. Then, the reward is as follows:
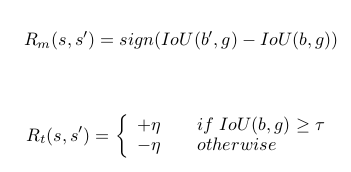
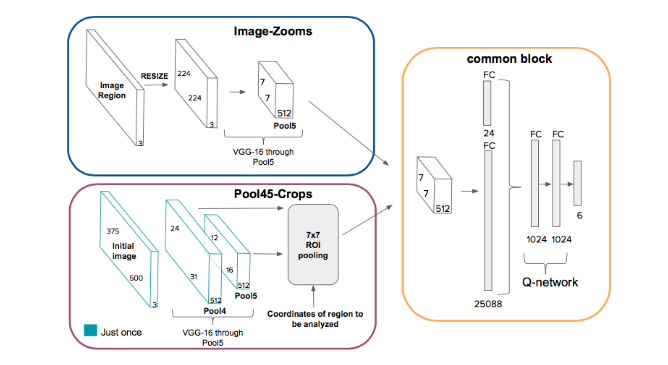
Network Architecture
They use a Q-network that takes as input the state representation discussed.
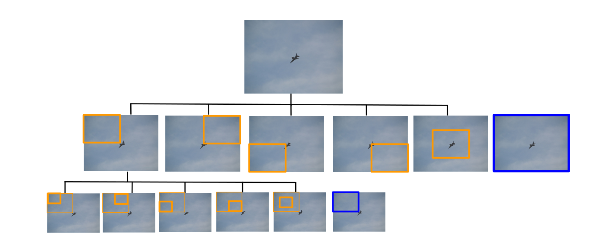
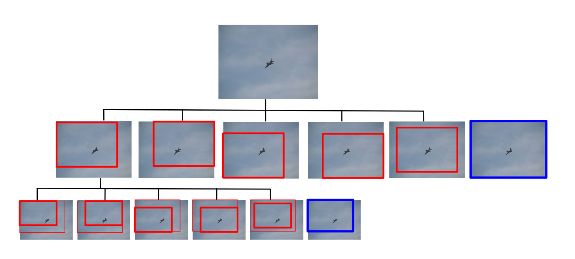
Qualitative Results

Why use Reinforcement Learing here?
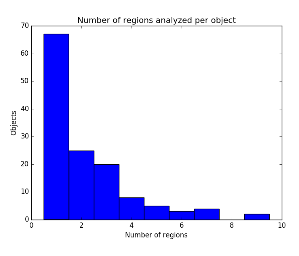
One gets curious as to why we should employ RL, if the results are at most equivalent to SOTA. An histogram of the amount of regions analyzed by the agent is shown. It is observed that the major part of objects are already found with a single step, which means that the object occupies the major part of the image. With less than 3 steps we can almost approximate all objects we can detect.
Note: All images have been taken from the Paper.