A Self-Adaptive Proposal Model for Temporal Action Detection based on Reinforcement Learning.
Problem Statement
The aim of the paper is to perform Action Detection Task, i.e. whether an action occurs somewhere in a video, and also when it occurs. In this paper, we propose a class-specific action detection model that learns to continuously adjust the current region to cover the groundtruth more precisely in a self-adapted way. This is achieved by applying a sequence of transformations to a temporal window that is initially placed in the video at random and finally finds and covers action region as large as possible. The sequence of transformation is decided by an agent that analyzes the content of the current attended region and select the next best action according to a learned policy, which is trained via reinforcement learning based on Deep Q-Learning algorithm. The results are computed on THUMOS’14 dataset.
Proposed Model Outcome
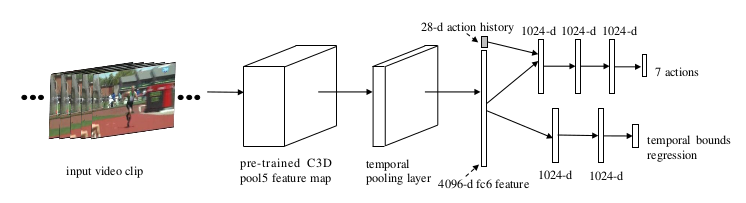
RL Components
The problem has been modeled as a Markov Decision Process. Formally, the MDP has a set of actions A, a set of states S, and a reward function R.
- Actions The set of actions A can be divided into two categories: one group for transformation on temporal window, such as “move left”, “move right”, “expand left”, and the remaining one for terminating the search, “trigger”. The transformation group includes regular actions that comprises of translation and scale, and one irregular action. The regular actions vary the current window in terms of position or time span around the attended region, such as “move left”, “expand left” or “shrink”, which are adopted by the agent to increase the intersection with the groundtruth that has overlaps with the current window. The irregular action, namely “jump”, translates the window to a new position away from the current site to avoid that the agent traps itself round the present location when there is no motion occurring nearby.

-
State Space The state of MDP is the concatenation of two components: the presentation of current window and the history of taken actions. To describe the motion within current window generally, the feature extracted from the C3D CNN model, which is pretrained on Sports-1M and finetuned on UCF-101, is utilized as the presentation.
-
Rewards The reward function R(s, a) provides a feedback to the agent when it performs the action a at the current state s, which awards the agent for actions that will bring about the improvement of motion localization accuracy while gives the punishment for actions that leads to the decline of the accuracy. The quality of motion localization is evaluated via the simple yet indicative measurement, Intersection over Union (IoU) between current attended temporal window and the groundtruth.
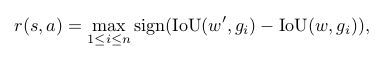
The trigger has a different reward scheme because it leads to a terminal state that does not change the box, and thus, the differential of IoU will always be zero for this action. The reward for the trigger is a thresholding function of IoU as follows:
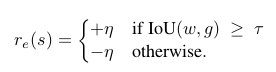
Regressor Network
Inspired by Fast R-CNN, where a regression network is incorporated to revise the position deviation between the predicted result and the groundtruth, we also introduce a regression model to refine the motion proposals. The regression channel accepts 4096-dimension feature vector as input and gives out two coordinate offsets on both starting and end moment. Unlike spatial bounding box regression, in which coordinate scaling is needed due to various camera-projection perspectives, we directly utilize original temporal coordinate (i.e. frame number) for offsets calculation leveraging the advantage of unified frame rate among video clips in our experiment. They use a Q-network that takes as input the state representation discussed.
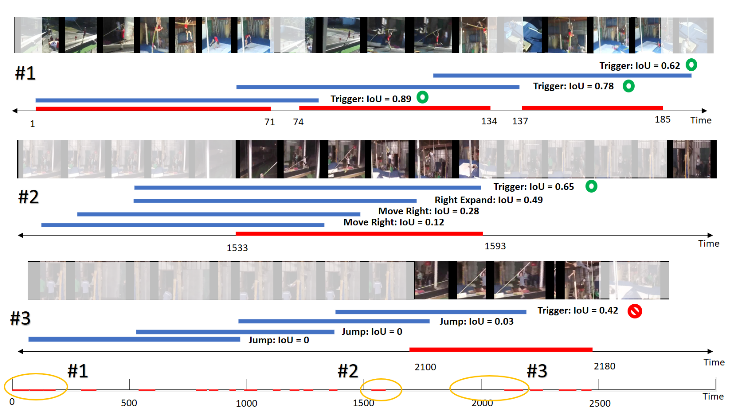
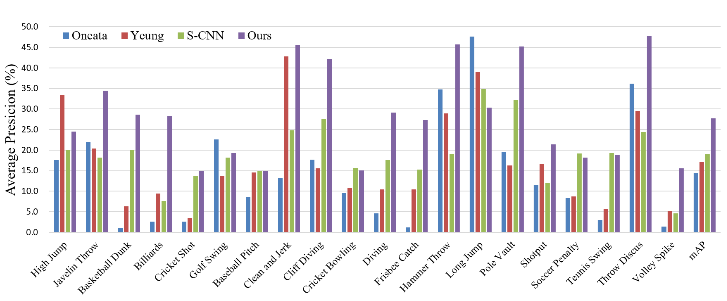
Qualitative Results
Some qualitative results are as follows.
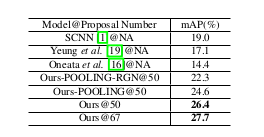
Quantitative Results
Comparison with other SOTA methods.
Why use Reinforcement Learing here?
One gets curious as to why we should employ RL, if the results are at most equivalent to SOTA. It is shown that agents guided by the proposed model are able to localize a single instance of an action after analyzing only few frames of a video. The run-time property of the method is dependent on the DQN’s performance. For a well trained DQN agent, it will concentrate on the ground truth in a couple of steps once it perceives the action segment. Meanwhile, it can also accelerate the exploring process over the video with “jump” action. Besides, the selection of scalar α is also an important factor that will influence the run-time performance. A large α will make the agent take a brief glance over the video in most of the case, but will also result in coarse proposals. As a trade off,we set the α = 0.2 during the training and testing phase.
Note: All images have been taken from the Paper.