Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning.
Problem Statement
This paper proposes a novel tracker which is controlled by sequentially pursuing actions learned by deep reinforcement learning. In contrast to the existing trackers using deep networks, the proposed tracker is designed to achieve a light computation as well as satisfactory tracking accuracy in both location and scale. The deep network to control actions is pre-trained using various training sequences and fine-tuned during tracking for online adaptation to target and background changes. Through evaluation of the OTB dataset, the proposed tracker is validated to achieve a competitive performance that is three times faster than state-of-the-art, deep network–based trackers.
Proposed Model Outcome
RL Components
The problem has been modeled as a Markov Decision Process. Formally, the MDP has a set of actions A, a set of states S, and a reward function R.
- Actions The action space A consists of eleven types of actions including translation moves, scale changes, and stopping action. The translation moves include four directional moves, {left, right, up, down} and also have their two times larger moves. The scale changes are defined as two types, {scale up, scale down}, which maintain the aspect ratio of the tracking target. Each action is encoded by the 11-dimensional vector with one-hot form.
-
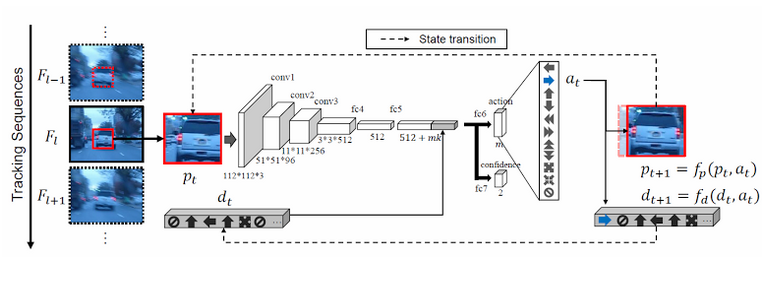
State Space The state is defined as a tuple (p, d), where p denotes the image patch within the bounding box (we call simply “patch” in the following) and d represents the dynamics of actions denoted by a vector (called by “action dynamics vector” in the following) containing the previous k actions.
-
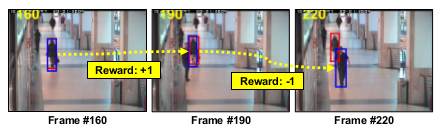
Rewards The reward function is defined as r(s) since the agent obtains the reward by the state s regardless of the action a. The reward $r(s_{t})$ keeps zero during iteration in MDP in a frame. At the termination step T, that is, a T is ‘stop’ action, $r(s_T)$ is assigned by,
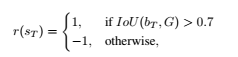
Network Architecture
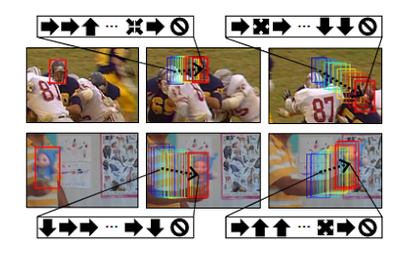
Qualitative Results
Some qualitative results are as follows.
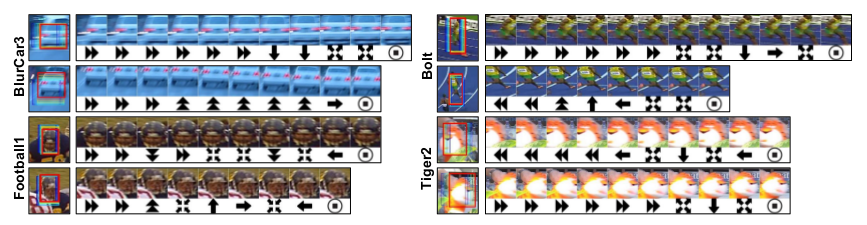
Quantitative Results
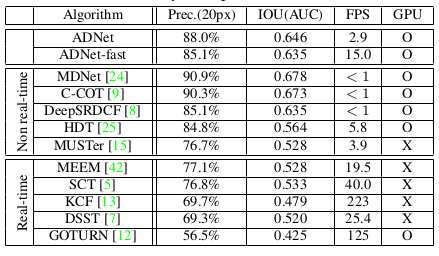
Comparison with other SOTA methods.
Why use Reinforcement Learing here?
Reinforcement learning makes the use of partially labeled data possible, which could greatly benefit actual applications. According to the evaluation results, the proposed tracker achieves a state-of-the-art performance in 3 fps, which is three times faster than the existing deep network-based trackers adopting a tracking-by-detection strategy. Furthermore, the fast version of the proposed tracker achieves a real-time speed (15 fps) with an accuracy that outperforms state-of-the-art real-time trackers.
Note: All images have been taken from the Paper.