
Research Overview
My research focuses on symbolic geometry—structured, interpretable representations that describe how shapes and other visual forms are constructed and related. Such representations promise powerful ways to reason about, create, and fabricate geometry, yet remain difficult to design and use. My work addresses this challenge across three fronts: formulation, acquisition, and manipulation.
Formulation. Many domains still lack symbolic representations that capture their physical, aesthetic, or functional constraints. In prior research, I designed domain-appropriate symbolic representations—each tuned to its context. MiGumi introduces a language for describing millable geometry that reflects CNC fabrication limits; ParSEL defines a language for parameterized shape edits; and Pattern Analogies formalizes symbolic representations for 2D visual patterns. These efforts explore how new formulations can make it easier to express geometry in various domains.
Acquisition. Even with a suitable representation, obtaining it from real data is challenging. I study both interactive and automated ways to infer symbolic structure from visual data. MiGumi provides design tools for describing integral joints under fabrication constraints, while SIRI (ICCV 2023) learns to infer and refine symbolic structure from shapes or images through self-supervision. Currently, I am working on techniques that extend these ideas toward large-scale text-to-geometry models to infer structured 3D representations from unstructured data.
Manipulation. Finally, once symbolic data exists, it must be made usable. Editing structured geometry can be tedious, so I develop systems that make manipulation intuitive: ParSEL translates natural language into parameterized edits, and Pattern Analogies performs structure-aware visual edits on complex patterns based on input examples on simple patterns. These approaches bridge symbolic reasoning and human intent, making structured geometry easier to work with.
What this enables. Lowering the barriers across formulation, acquisition, and manipulation paves the way for a Cambrian explosion of domain-specific geometry languages—each tailored to real constraints and creative goals. This evolution will make it easier to invent new symbolic forms, build tools around them, and ultimately enrich how we represent and reason about the visual world.
Past Research
Previously, I worked as a Researcher at Preferred Networks, Japan, and, before that, as a Research Assistant at Video Analytics Lab, IISc, Bangalore, India. I have worked on various projects in Computer Vision, Machine Learning, Audio Processing, Human-Computer Interaction, and Robotics. I have been really fortunate to collaborate and get mentorship from some amazing people - Daniel Ritchie, R Venkatesh Babu, Siddhartha Chaudhuri, Shin-ichi Maeda, Adrien Gaidon, Rares Ambrus, Jason Naradowsky, and Fabrice Matulic to name a few.
Some of the central themes in my previous research:
- Novel methods for Computer Vision tasks (Semantic Segmentation, 3D Object Pose estimation, etc.),
- Stability of deep learnt features (Adversarial Attacks),
- Application of DL in Audio (source separation) and HCI (Tracking in VR).
For a complete list of published papers, visit Google Scholar.
Publications:
Residual Primitive Fitting of 3D Shapes with SuperFrusta
A. Ganeshan, Matheus Gadelha, Thibault Groueix, Zhiqin Chen, Siddhartha Chaudhuri, Vladimir G. Kim, Wang Yifan and Daniel Ritchie
Oral & Award Candidate (1.8%) IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) 2026
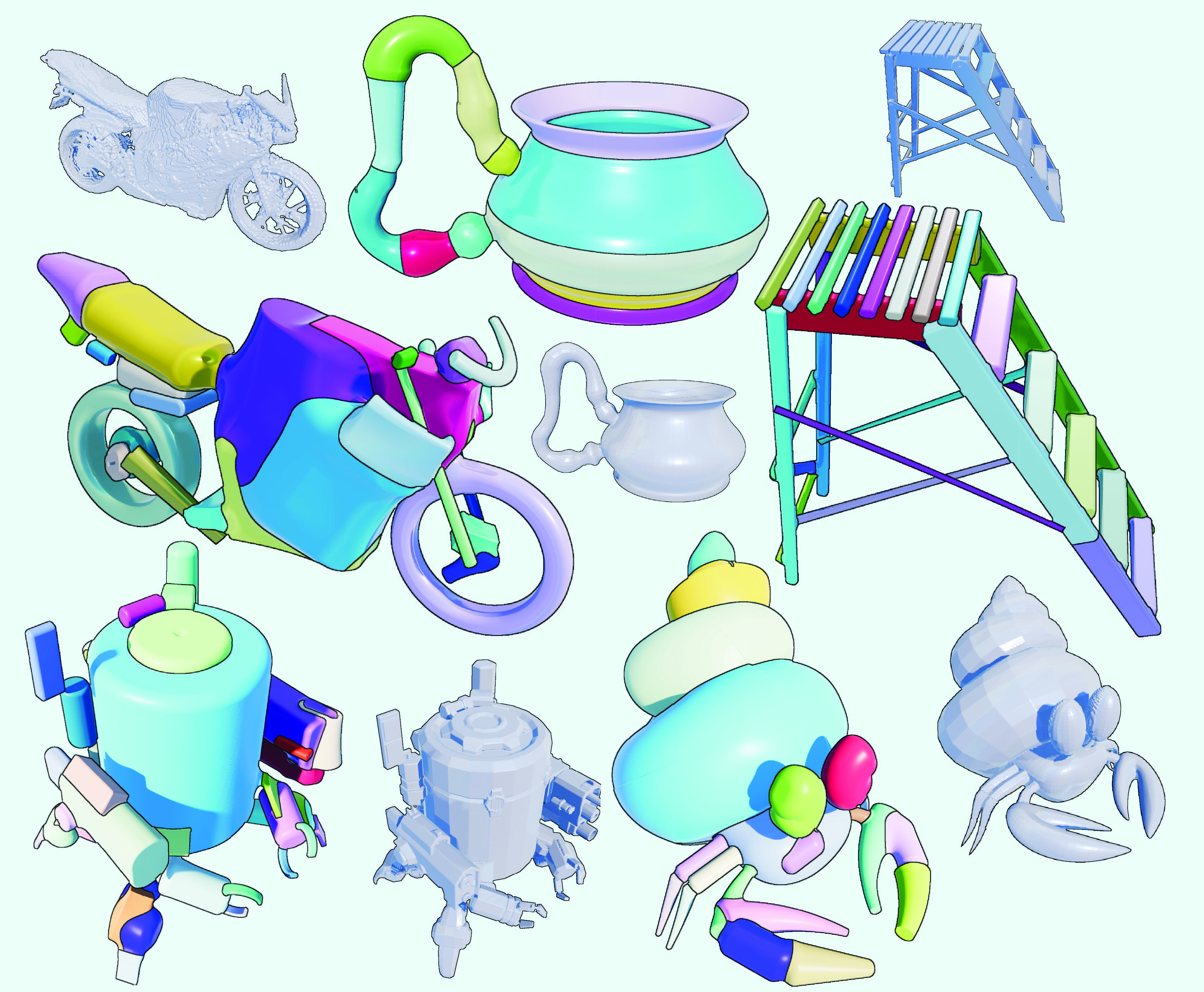
We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives. Our approach combines SuperFrustum, an expressive, editable, and optimizable primitive, with ResFit, an iterative fitting algorithm that achieves state-of-the-art reconstruction quality while using significantly fewer primitives than prior work.
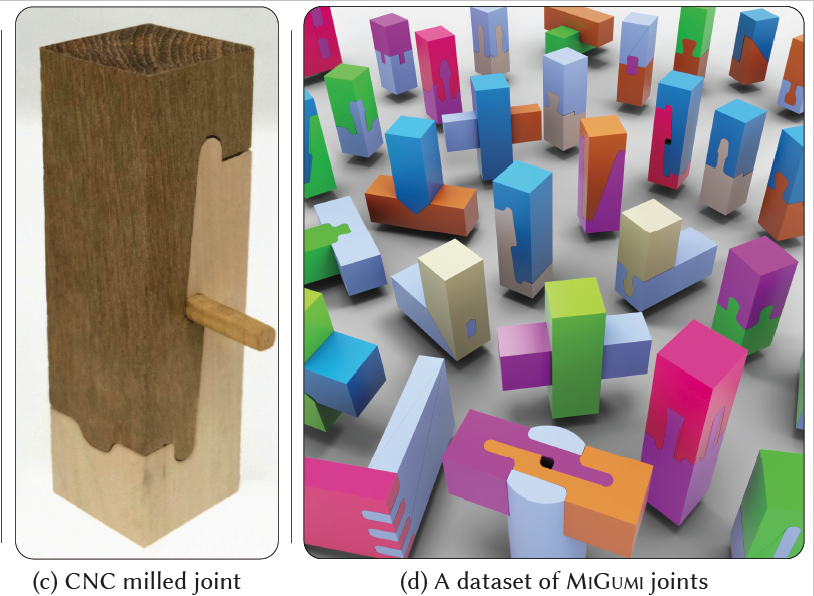
MiGumi - Making Tightly Coupled Integral Joints Millable
A. Ganeshan, Kurt Fleischer, Wenzel Jakob, Ariel Shamir, Daniel Ritchie, Takeo Igarashi and Maria Larsson
ACM Siggraph Asia 2025, Journal at Transactions on Graphics (TOG) 2025
We introduce MXG, a language for representing geometry as milling operations with flat-end drill bits, enabling traditional integral wood joints to be adapted for CNC fabrication. Through gradient-based co-optimization of part geometries, we restore tight coupling between parts despite milling-induced artifacts like rounded corners.

Procedural Scene Programs for Open-Universe Scene Generation - LLM-Free Error Correction via Program Search
Maxim Gumin, Do Heon Han, Seung Jean Yoo, A. Ganeshan, R. Kenny Jones, Kailiang Fu, Rio Aguina-Kang, Stewart Morris, Daniel Ritchie
ACM Siggraph Asia 2025, Journal at Transactions on Graphics (TOG) 2025
We introduce procedural scene programs, an imperative paradigm where LLMs iteratively place objects as functions of previously-placed objects, handling wider variety and complexity than declarative constraint-based approaches. Our LLM-free error correction via program search iteratively improves scene validity while preserving layout intent, with participants preferring our approach 82-94% of the time.

Pattern Analogies - Learning to Perform Programmatic Image Edits by Analogy
A. Ganeshan, Thibault Groueix, Paul Guerrero, Radomír Měch, Matthew Fisher and Daniel Ritchie
IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) 2025
We enable programmatic editing of pattern images through pattern analogies—pairs of simple patterns demonstrating the intended edit. Using our SplitWeave DSL and TriFuser (a specialized Latent Diffusion Model), our method performs structure-aware edits while generalizing to unseen pattern styles.
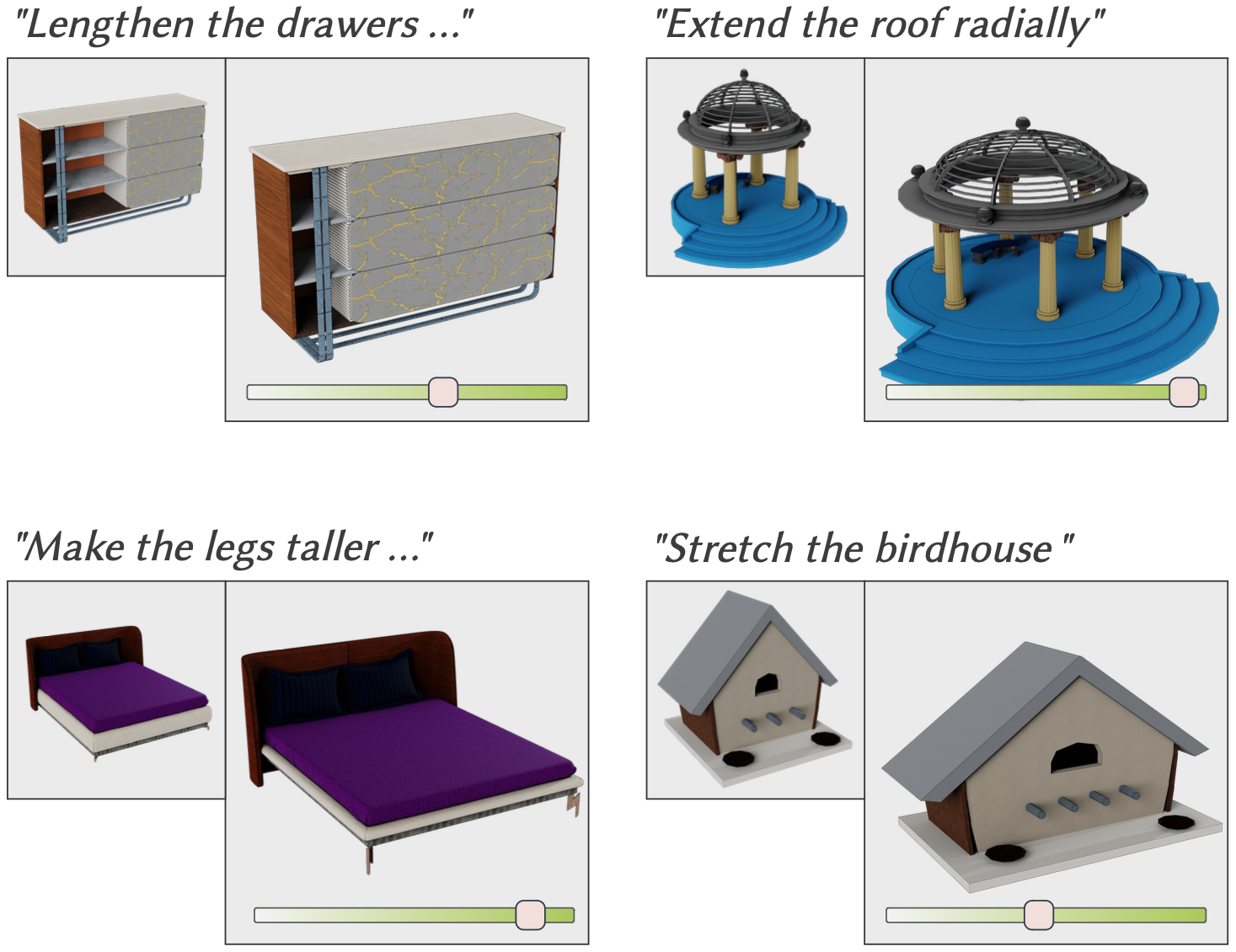
ParSEL - Parameterized Shape Editing with Language
A. Ganeshan, Ryan Y. Huang, Xianghao Xu, R. Kenny Jones and Daniel Ritchie
ACM Siggraph Asia 2024, Journal at Transactions on Graphics (TOG) 2024.
We enable controllable editing of 3D shapes from natural language by producing parameterized editing programs users can adjust to explore variations. Our Analytical Edit Propagation (AEP) algorithm leverages computer algebra systems to extend LLM-generated seed edits into complete, semantically-valid programs.

Learning to Edit Visual Programs with Self-Supervision
R Kenny Jones, Renhao Zhang, A. Ganeshan, Daniel Ritchie
Conference on Neural Information Processing Systems (NeurIPS), 2024
We train an edit network that predicts local edit operations to improve visual programs' similarity to target images, learning through self-supervised bootstrapped finetuning. Our editing-based inference paradigm, which evolves populations initialized from one-shot predictions, significantly outperforms using only one-shot models.
Creating Language-driven Spatial Variations of Icon Images
Xianghao Xu, A. Ganeshan, Karl DD Willis, Yewen Pu, Daniel Ritchie
Arxiv
We enable language-driven spatial editing of icon images by translating user requests into geometric constraints using LLMs and a DSL library. Optimizing affine transformations of icon segments with respect to these constraints produces spatially varied icons while preserving physical and logical coherence.
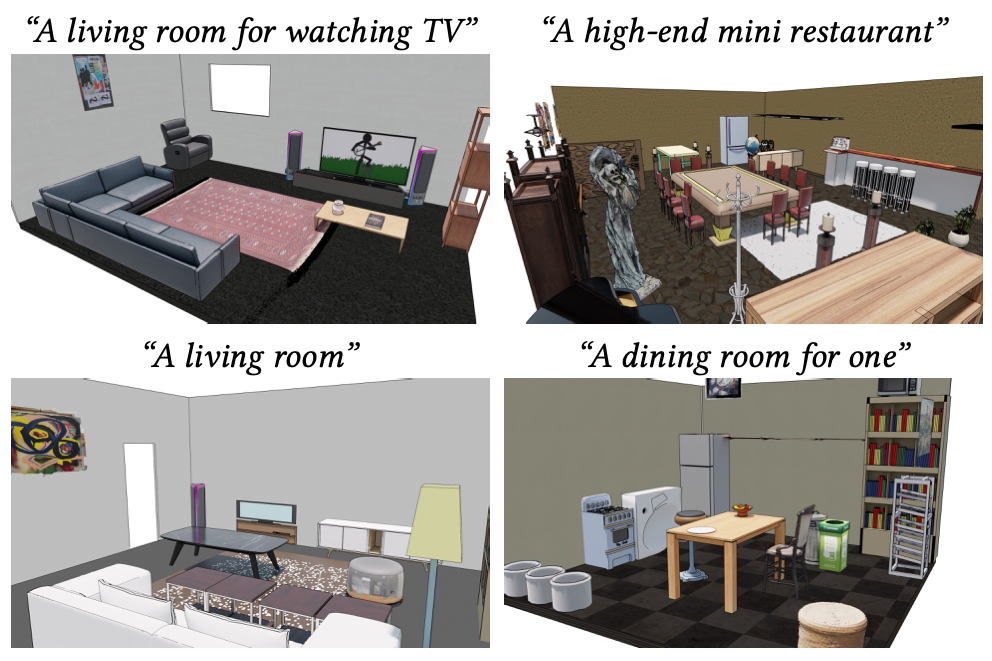
Open-universe indoor scene generation using llm program synthesis and uncurated object databases
Rio Aguina-Kang, Maxim Gumin, Do Heon Han, Stewart Morris, Seung Jean Yoo, A. Ganeshan, R Kenny Jones, Qiuhong Anna Wei, Kailiang Fu, Daniel Ritchie
Arxiv
We generate indoor scenes from text prompts by leveraging LLMs to synthesize programs in a layout DSL, solving constraints via gradient optimization, and retrieving meshes from uncurated databases using VLMs. Our open-universe approach handles arbitrary prompts and object categories without requiring large 3D scene training datasets.

Improving Unsupervised Visual Program Inference with Code Rewriting Families
A. Ganeshan, R. Kenny Jones and Daniel Ritchie
Oral (9.03%) IEEE / CVF International Conference on Computer Vision (ICCV), 2023
We introduce SIRI, a framework for bootstrapped learning that improves visual program inference by sparsely applying code rewriters—Parameter Optimization, Code Pruning, and Code Grafting. Our family of rewriters produces more parsimonious programs with fewer primitives while matching or outperforming domain-specific neural architectures.
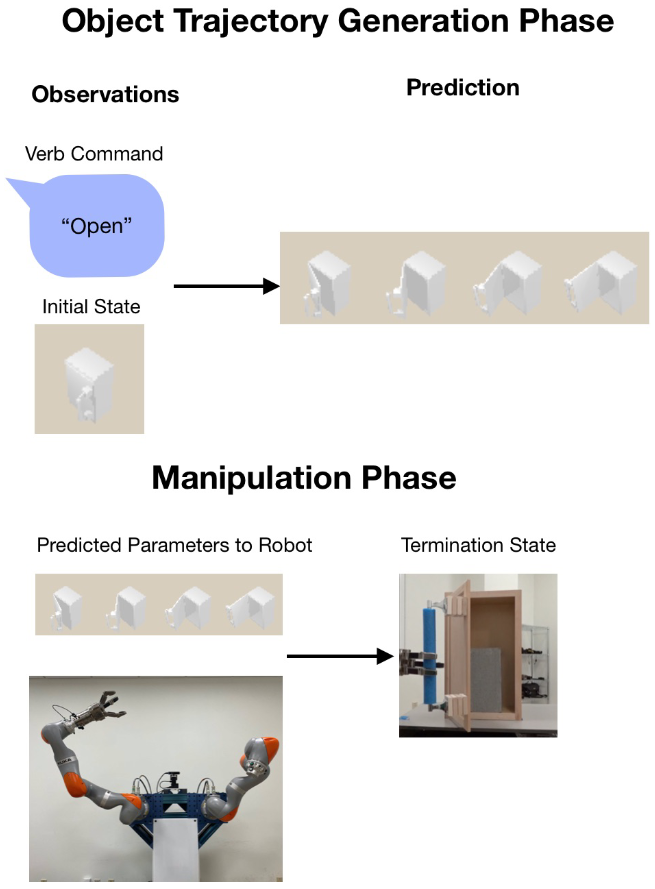
Skill Generalization with Verbs
R. Ma, L. Lam, B. A. Spiegel, A. Ganeshan, B. Abbatematteo, R. Patel, D. Paulius, S. Tellex, G. Konidaris.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023
We enable robots to generalize manipulation skills to novel objects using verbs as semantic abstractions. Our probabilistic classifier learns verb-trajectory associations and performs policy search to generate executable trajectories for new object instances.
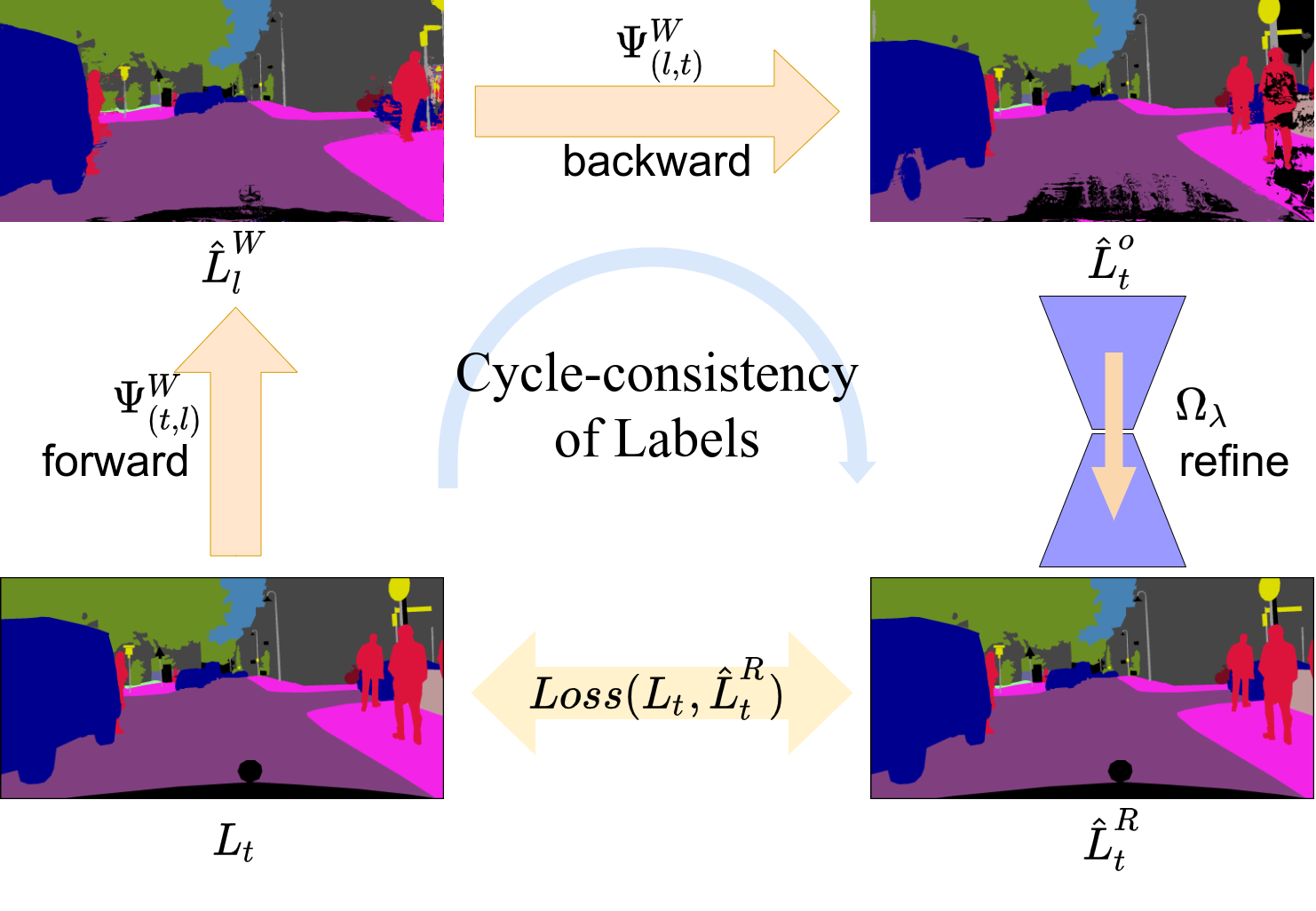
Warp-Refine Propagation Semi-Supervised Auto-labeling via Cycle-consistency
A. Ganeshan , Alexis Vallet, Yasunori Kudo, Shin-ichi Maeda, Tommi Kerola, Rares Ambrus, Dennis Park, Adrien Gaidon
IEEE / CVF International Conference on Computer Vision (ICCV), 2021
We propose Warp-Refine Propagation, a label propagation method that combines geometric warping with learned semantic priors via cycle consistency for semi-supervised video annotation. Our approach improves label propagation by 13.1 mIoU on ApolloScape and achieves competitive results on semantic segmentation benchmarks.

Phonetroller - Visual Representations of Fingers for Precise Touch Input with Mobile Phones in VR
Fabrice Matulic, A. Ganeshan, Hiroshi Fujiwara, Daniel Vogel
Conference on Human Factors in Computing Systems, CHI 21
We enable precise touch input on smartphones in fully immersive VR by mounting a mirror above the screen to capture thumbs via the front camera. Deep learning infers fingertip positions, providing semi-transparent overlays that guide users to thumb-size targets without seeing their hands.
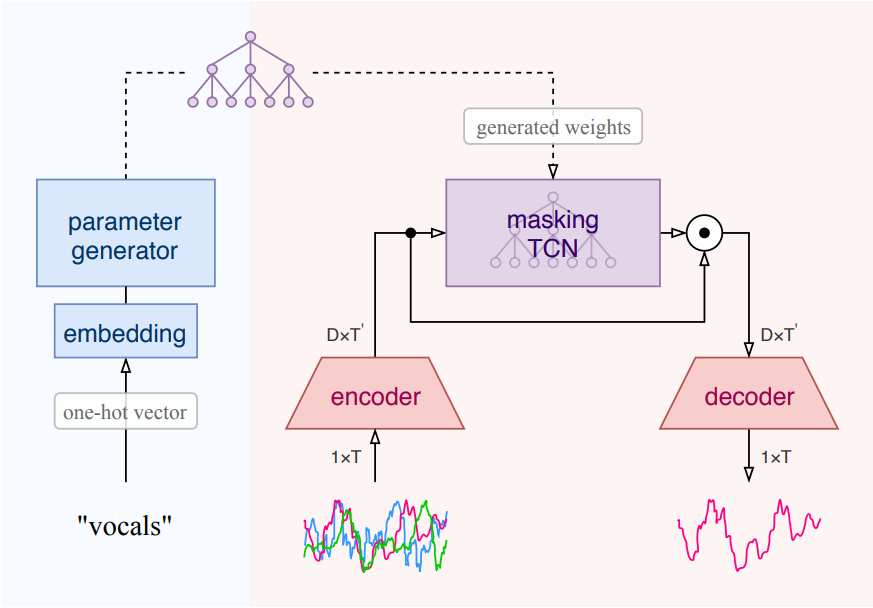
Meta-Learning Extractors for Music Source Separation
David Samuel, A. Ganeshan, Jason Naradowsky
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP-2020)
We propose Meta-TasNet, a hierarchical meta-learning model where a generator predicts weights for instrument-specific extractors in music source separation. This enables efficient parameter-sharing while achieving performance comparable to state-of-the-art with fewer parameters and faster runtime.

FDA Feature Disruptive Attack
A. Ganeshan, B. S. Vivek, R. V. Babu
IEEE / CVF International Conference on Computer Vision (ICCV), 2019
We propose Feature Disruptive Attack (FDA), an adversarial attack that corrupts features at each network layer rather than targeting outputs. FDA generates stronger adversaries that severely degrade deep network performance and disrupt feature-representation tasks even without access to task-specific networks.
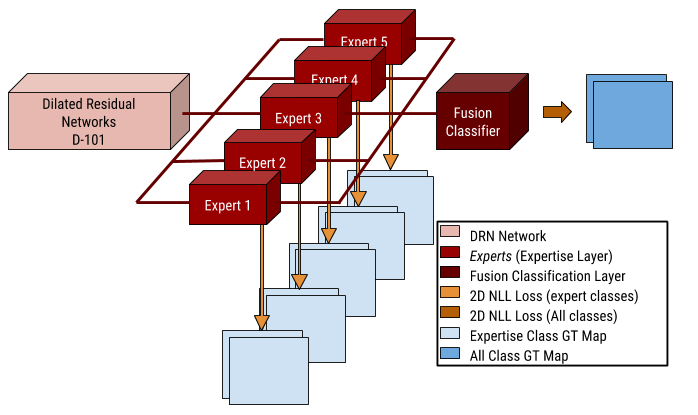
Enhancing Semantic Segmentation by Learning Expertise between Confusing Classes
A. Ganeshan, G. S. Rajput, R. V. Babu
First International Workshop On Autonomous Navigation in Unconstrained Environments, ECCV 18
We propose an Expertise-Layer to enhance semantic segmentation models' ability to discern differences between confusing classes in unconstrained datasets with high intra-class variations. Our approach improves performance on real-world scenarios with similar classes and low-shot categories.
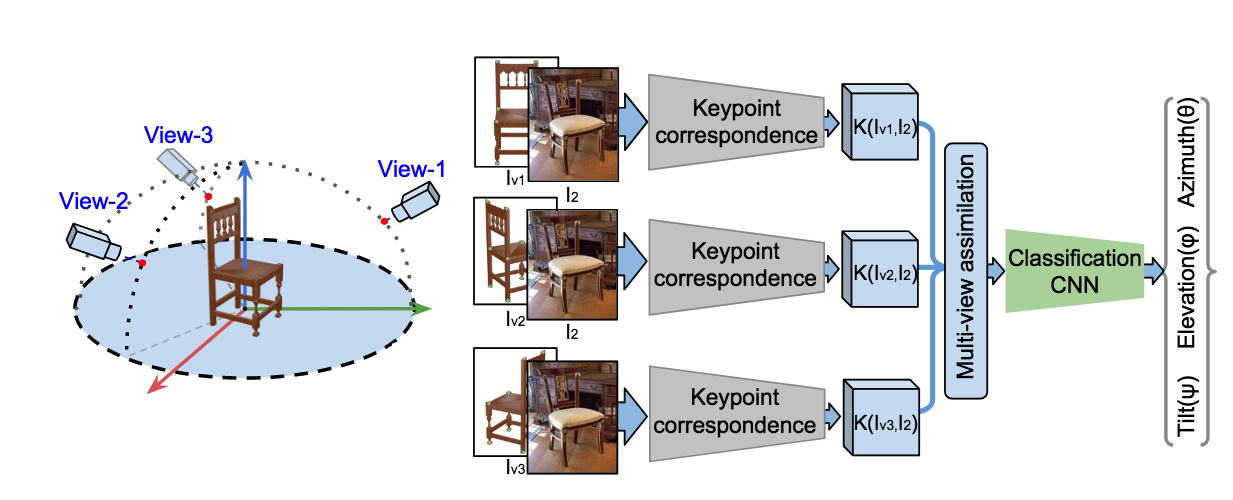
Object Pose Estimation from Monocular Image using Multi-View Keypoint Correspondence
J. N. Kundu*, A. Ganeshan*, M. V. Rahul*, R. V. Babu
Geometry Meets Deep Learning Workshop, at ECCV 2018.
We learn pose-invariant local descriptors from 2D RGB images and generate keypoint correspondence maps using renders of 3D template models. Fusing multi-view correspondence information improves geometric comprehension and enables state-of-the-art pose estimation while alleviating data scarcity.
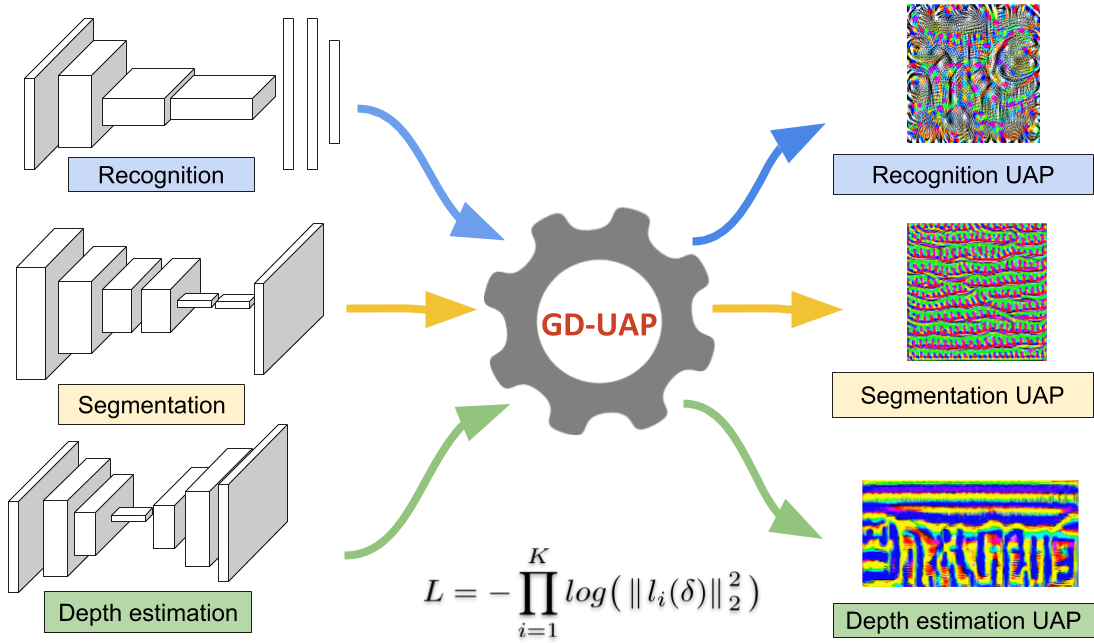
Generalizable Data-free Objective for Crafting Universal Adversarial Perturbations
K. M. Reddy*, A. Ganeshan*, R. V. Babu
IEEE Transactions on Patter Analysis and Machine Intelligence, 2018
We present a generalizable, data-free objective for crafting universal adversarial perturbations that works across multiple vision tasks by corrupting features at multiple layers. Our method outperforms data-dependent approaches in black-box scenarios and achieves significant fooling rates without requiring training data.
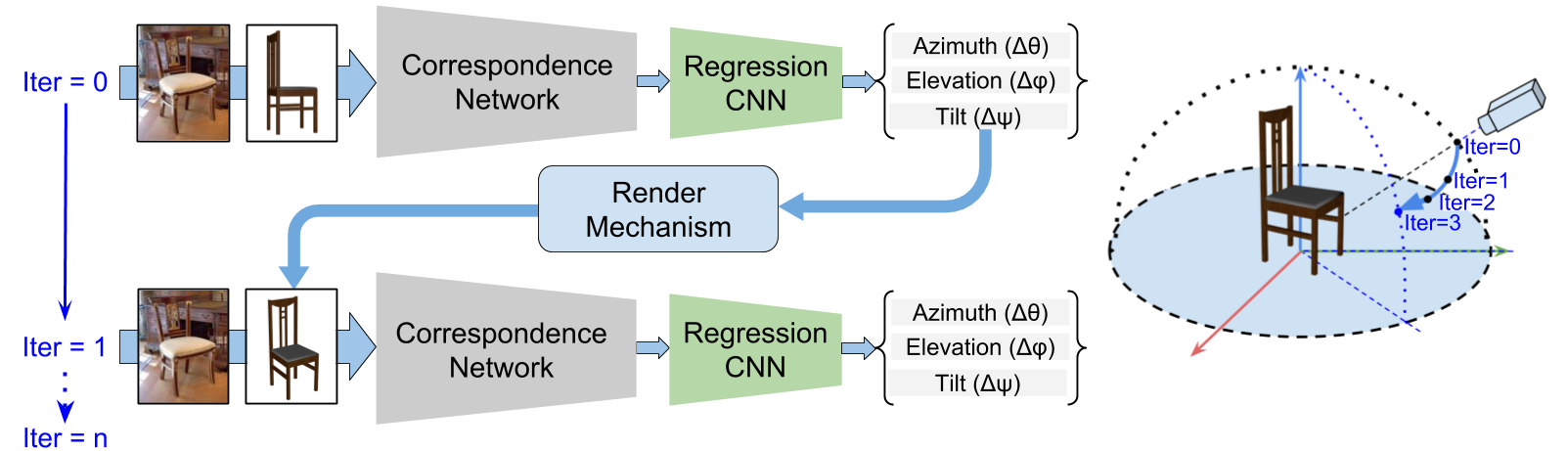
iSPA-Net Iterative Semantic Pose Alignment Network
J. N. Kundu*, A. Ganeshan*, M. V. Rahul*, R. V. Babu
ACM International Conference on Multimedia 2018
We estimate fine-grained 3D object pose by predicting viewpoint differences between image pairs, leveraging semantic structural regularity from 3D CAD models. Our iterative refinement framework uses online rendering and non-uniform bin classification to achieve state-of-the-art performance on real image datasets.